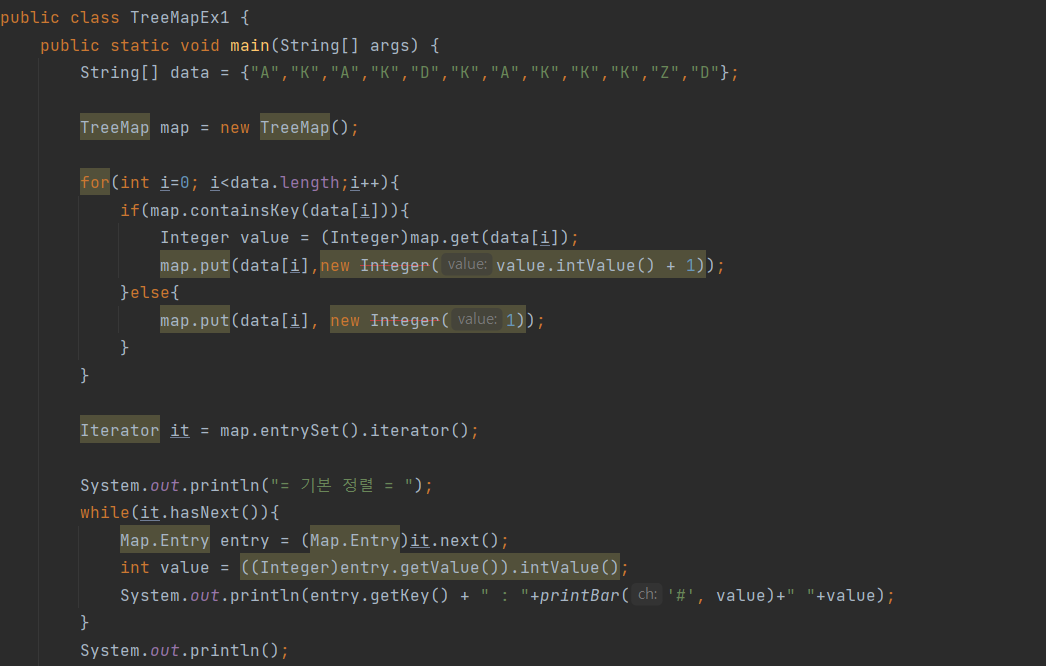
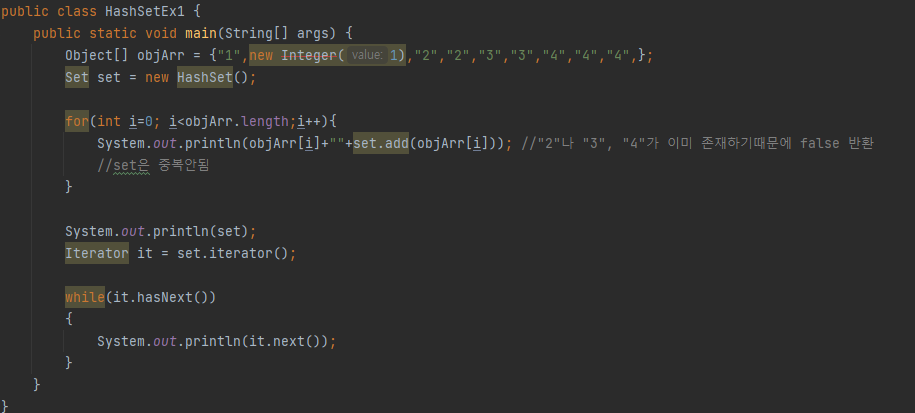
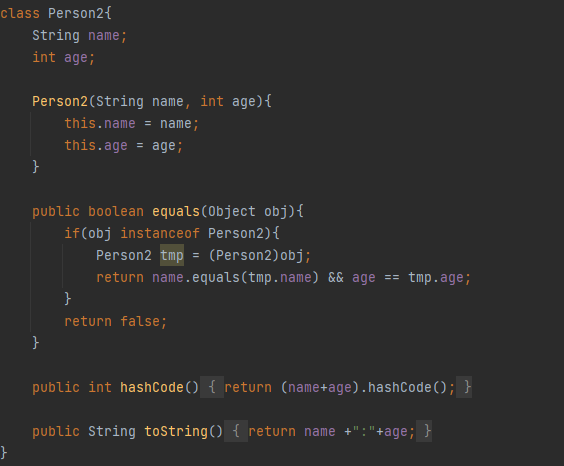
ArrayList
ArrayList는 List인터페이스를 조상으로 갖는 클래스이며 Object배열을 이용하여 데이터를 순차적으로 저장한다.
배열에 순차적으로 저장되며 배열에 더이상 저장할 공간이 없으면 보다 큰 새로운 배열을 생성하여 기존에 저장되어있던 데이터들을 복사하여 새로운 배열에 저장한다.
ArrayList의 메서드
생성자
ArrayList() : 크기가 10인 ArrayList를 생성한다.
ArrayList(Collection c) : 주어진 컬렉션이 저장된 ArrayList를 생성한다.
ArrayList(int initialCapacity) : 지정된 초기용량을 갖는 ArrayList를 생성한다.
추가
boolean add(Object o) : ArrayList의 마지막에 객체를 추가한다. 성공하면 true를 반환한다.
void add(int index, Object element) : index위치에 element객체를 저장한다. index와 index이후에 저장되어있던 객체들은 한칸씩 뒤로 이동한다.
boolean addAll(Collection c) : 주어진 컬렉션의 모든 객체를 저장한다.
boolean addAll(int index, Collection c) : index위치부터 컬렉션을 저장한다.
삭제
void clear() : ArrayList를 비운다. ArrayList에 존재하는 모든 객체들 삭제
Object remove(int index) : index위치에 존재하는 객체를 삭제한다. index 이후에 존재하는 객체들은 한칸씩 앞으로 이동한다.
boolean remove(Object o) : o와 일치하는 객체를 찾아 제거한다. 성공하면 true 실패하면 false
boolean removeAll(Collection c) : 컬렉션 c에 저장된 객체들과 일치하는 모든 객체들을 제거한다.
boolean retainAll(Collection c) : 컬렉션 c에 저장된 객체들과 일치하는 객체들만 남겨두고 다른 객체들은 모두 삭제한다.
검색
boolean contains(Object o) : ArrayList에 객체 o가 존재하는지 확인한다. 존재한다면 true 반환
Object get(int index) : index에 저장된 객체를 반환한다.
int indexOf(Object o) : 객체 o 와 일치하는 객체를 찾아 해당 객체의 index를 반환한다.
int lastIndexOf(Object o) : indexOf와 같은기능을 수행하지만 lastIndexOf는 ArrayList의 마지막부터 앞쪽으로 객체를 탐색한다.
변경
Object set(int index, Object element) : index위치에 element를 저장한다.
외의 메서드
Object clone() : ArrayList를 복사한다.
void ensureCapacity(int minCapacity) : ArrayList의 용량이 최소한 minCapacity가 되도록 한다.
boolean isEmpty() : ArrayList가 비어있는지 확인한다.
Iterator iterator() : ArrayList의 Iterator객체를 반환
ListIterator listIterator() : ArrayList의 ListIterator를 반환
ListIterator listIterator(int index) : ArrayList의 index부터 시작하는 Iterator 반환
int size() : ArrayList에 저장된 객체의 수를 반환
void sort(Comparator c) : 정렬기준 c로 ArrayList를 정렬
List subList(int fromIndex, int toIndex) : fromIndex부터 toIndex사이에 저장된 객체를 반환한다.
Object[] toArray() : ArrayList에 저장된 모든 객체들을 객체배열로 반환한다.
Object[] toArray(Object[] a) : ArrayList에 저장된 모든 객체들을 객체배열 a에 담아 반환한다.
void trimToSize() : 빈공간, 공백을 지워 용량을 크기에맞게 줄인다.



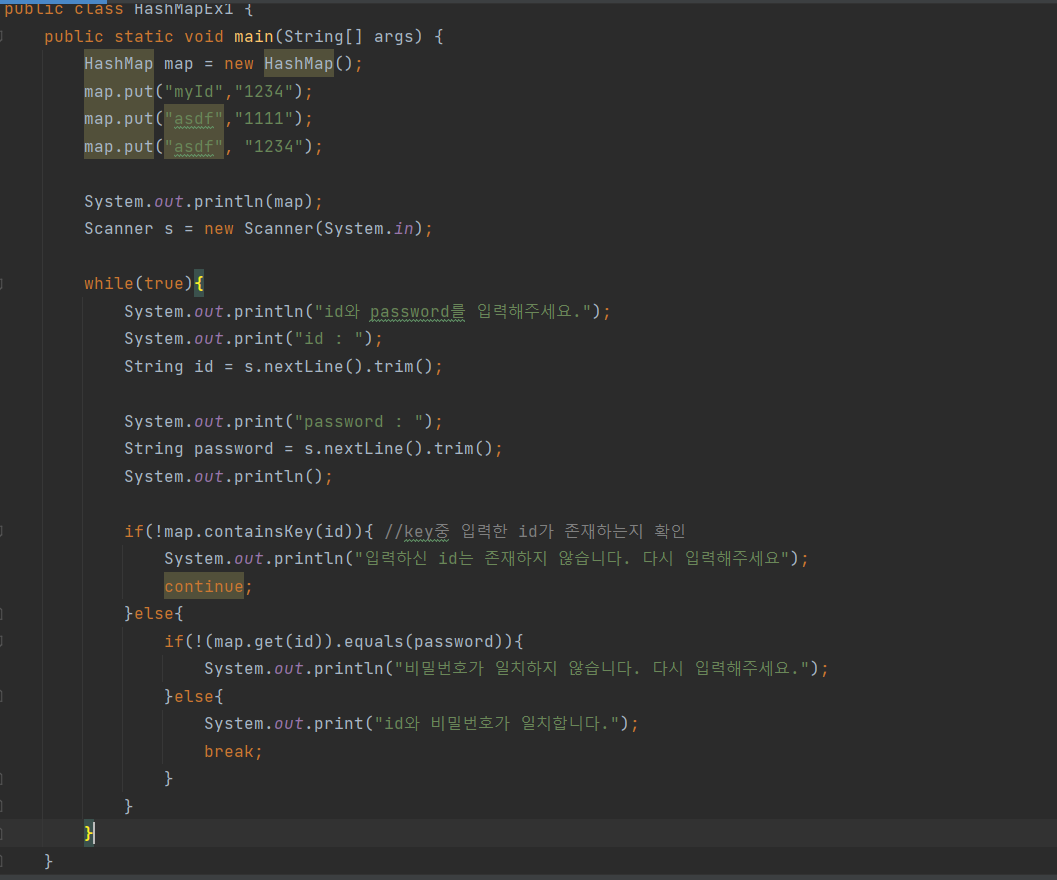
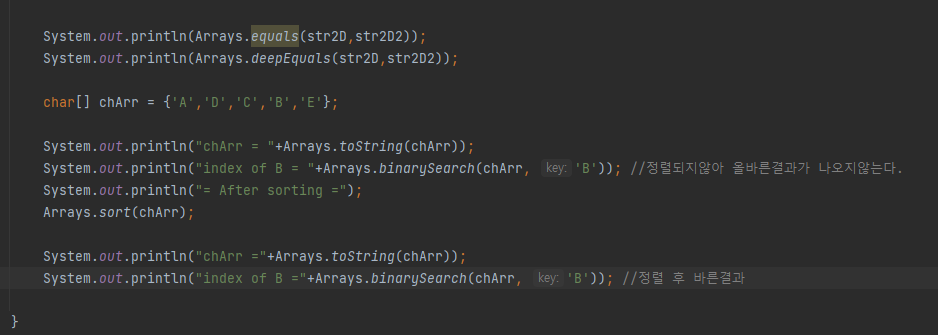
ArrayList에서 삭제연산시 for문에서 변수 i를 증가시키는 식으로 삭제를 할경우 원하는 결과를 얻기 어려울 수 있다.
왜냐하면 ArrayList에 존재하는 객체를 삭제할경우 해당 빈칸을 삭제한 index의 이후 객체들이 빈칸을 채우기 때문이다.
삭제연산을 해야할경우 마지막요소부터 앞으로 순서대로 탐색하며 삭제하는 것이 좋다.
LinkedList
배열의 단점
1.크기를 변경이 불가능하다.
-크기 변경이 불가능하기 때문에 더 큰크기의 새로운 배열을 생성하여 값을 복사하애야한다.
-충분히 더 큰 크기의 배열을 생성하는 과정에서 메모리가 낭비된다.
2.비순차적 데이터의 추가 및 삭제에 시간이 많이걸린다.
-배열의 중간에 데이터를 추가하면 빈공간을 만들기 위해 다른 데이터들을 복사하여 이동시켜야한다.
-배열의 중간에 데이터를 삭제하면 빈공간을 채우기 위해 다른 데이터들을 복사하여 이동시켜야한다.
배열을 단점을 보완하기 위해 링크드 리스트(Linked List)라는 자료구조가 생성되었다.
링크드 리스트는 불연속적으로 존재하는 데이터를 서로 연결(link)한 형태로 구성되어있다.

링크드 리스트는 각요소들은 자신과 연결된 다음 요소에 대한 주소와 데이터로 구성되어있다.
링크드리스트에서의 삭제와 추가는 간단하다. 삭제의 경우 삭제하고자하는 노드의 이전노드가 다음노드로 삭제할노드의 다음노드를 가리키면 연결은 유지되면서 노드삭제가 가능하다.
추가 또한 노드를 생성하고 생성한 노드의 이전노드가 다음노드로 생성한노드를 가리키게하면되고 기존에 가리키던 다음노드를 생성된 노드가 가리키면 된다.
위의 그림은 단방햔 링크드리스트이지만 이전노드를 가리키는 더블링크드 리스트도 있다.
더블링크드 리스트는 단방향 링크드리스트와 다르게 이전노드에 대한 접근도 간편하다.
자바의 LinkedList클래스는 더블링크드 리스트 구조로 구현되어있다. 또한 Queue인터페이스와 Deque인터페이스를 구현하도록 되어있다.
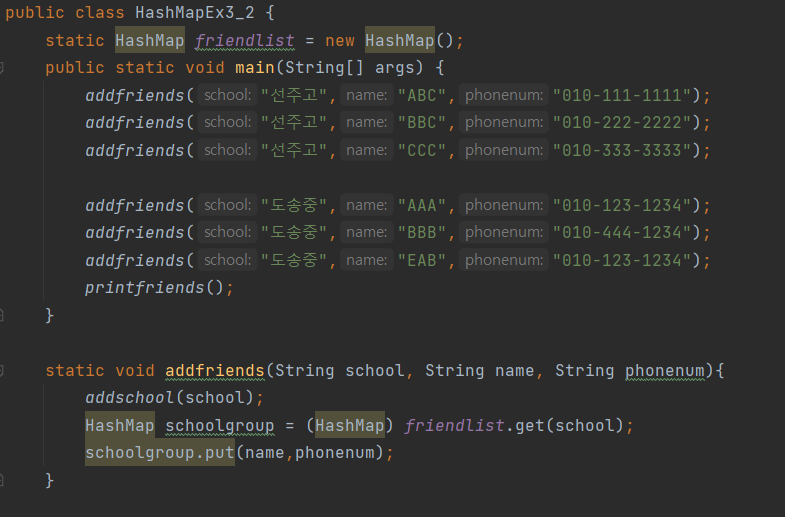
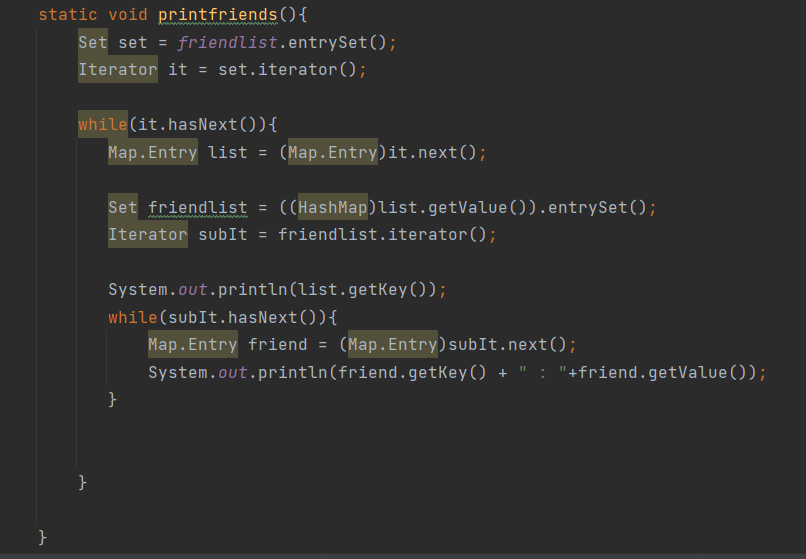
LinkedList의 메서드
생성자
LinkedList() : LinkedList객체 생성
LinkedList(Collection c) : 컬렉션 c를 포함하는 LinkedList생성
추가
boolean add(Object o) : 객체 o 를 LinkedList의 끝에 추가한다. 성공하면 true, 실패하면 false
void add(int index, Object element) : index 위치에 element 객체를 추가
boolean addAll(Collection c) : 컬렉션 c의 모든 요소들을 LinkedList에 추가. 성공하면 true, 실패하면 false
boolean addAll(int index, Collection c) : index위치에 컬렉션 c의 모든 요소들 추가. 성공하면 true, 실패하면 false
boolean offer(Object o) : 객체 o를 LinkedList의 끝에 추가한다.
void addFirst(Object o) : 객체 o를 LinkedList 맨앞에 추가
void addLast(Object o) : 객체 o를 LinkedList 맨뒤에 추가
boolean offerFirst(Object o) : 객체 o를 LinkedList 맨앞에 추가
boolean offerLast(Object o) : 객체 o 를 LinkedList 맨뒤에 추가
void push(Object o) : addFirst()와 동일하다.
삭제
void clear() : LinkedList의 모든 요소를 삭제한다.
Object remove(int index) : index의 객체를 LinkedList에서 삭제한다.
boolean remove(Object o) : 객체 o를 LinkedList에서 제거한다.
boolean removeAll(Collection c) : Collection c에 존재하는 객체들과 일치하는 요소들을 모두 삭제한다.
boolean retainAll(Collection c) : Collection c에 존재하는 객체들과 일치하는 요소들만 남겨두고 나머지는 삭제한다.
Object poll() : LinkedList의 첫번째 요소를 반환. 제거한다.
Object remove() : LinkedList의 첫번째 요소를 제거한다.
Object pollFirst() : LinkedList의 첫번쨰 요소를 반환하면서 제거
Object pollLast() : LinkedList의 마지막 요소를 반환
Object pop() : removeFirst()와 동일하다.
Object removeFirst() : 첫번째요소를 제거한다.
Object removeLast() : 마지막요소를 제거한다.
boolean removeFirstOccurrence(Object o) : LinkedList에서 첫번째로 일치하는 객체를 제거한다.
boolean removeLastOccurrence(Object o) : LinkedList에서 마지막으로 일치하는 객체를 제거한다.
탐색
boolean contains(Object o) : 지정된 객체가 LinkedList에 포함되어있는지 알려줌
boolean containsAll(Collection c) : 지정된 컬렉션의 모든 요소가 포함되어있는지 알려줌
Object get(int index) : 지정된 위치의 객체를 반환
int IndexOf(Object o) : 지정된 객체가 저장된 위치를 반환
Object peek() : LinkedList의 첫번째 요소 반환
Object getFirst() : LinkedList 첫번째 요소 반환
Object getLast() : 마지막 요소반환
Object peekFrist() : LinkedList의 첫번째 요소 반환
Object peekLast() : LinkedList 첫번째 요소 반환
ArrayList, LinkedList 비교
1.순차적으로 추가/삭제 하는 경우 ArrayList가 더 빠르다.
2.중간 데이터를 추가/삭제 하는 경우 LinkedList가 더 빠르다.
3.데이터의 개수가 많아질수록 데이터를 읽어오는 시간은 불연속적인 LinedList가 더 오래걸린다.