Recursive 함수내의 Recursive 함수가 호출되면, Recursive 함수의 복사본이 만들어져서 복사본이 실행되는 구조로 재귀함수를 진행한다.
RecursiveFunc.c
함수를 구성하는 명령문은 CPU로 이동이 되어서(복사가 되어서)실행이 된다. 그런데 이 명령문은 얼마든지 CPU로 이동이(복사가) 가능하다. 즉 Recursive함수의 중간까지 명령문을 실행하다가 다시 Recursive함수의 앞부분에 위치한 명령문을 CPU로 이동시키는 것은 문제가 되지 않는다.
또한 위 코드처럼 재귀함수를 정의하는데 있어서 탈출조건을 구성하는 것은 매우 중요한일이다.
재귀의 활용
피보나치 수열 : Fibonacci Sequence
피보나치 수열은 재귀적인 형태를 띄는 대표적인 수열로서 앞엣것 두개를 더해서 현재의 수를 만들어가는 수열이다. 첫번째, 두번째 값은 0,1로 고정이고 세번째부터 앞의 두수를 더하여 수열을 만들어간다.
자료구조가 '데이터의 표현 및 저장 방법' 이라면, 알고리즘은 표현 및 저장된 데이터를 대상으로 하는 '문제 해결 방법'이다.
-> 자료구조가 결정되면 그에 따른 효율적인 알고리즘을 결정할 수 있다.
알고리즘은 자료구조에 의존적이다.
알고리즘 성능 분석 방법
잘 동작하고 좋은 성능을 보장받기를 원한다면 자료구조와 알고리즘을 분석하고 평가할 수 있어야 한다.
자료구조와 알고리즘을 평가하는 두가지 요소는 '속도'와 '메모리 사용량' 이다.
속도에 해당하는 수행시간 분석결과를 '시간 복잡도(time complexity)' 라고 하고, 메모리 사용량에 대한 분석 결과를 '공간 복잡도(space complexity)'라고 한다.
알고리즘 수행 속도 평가 방식
1.연산의 횟수
2.데이터의 수 n에 대한 연산횟수 T(n) 구성.
함수 T(n)을 구성하면 데이터 수의 변화에 따른 연산 횟수 변화를 한눈에 파악할 수 있어, 둘 이상의 알고리즘을 비교하기 용이해진다.
데이터 수에 따라 연산횟수도 달라지기 때문에 상황에 맞는 알고리즘을 찾아야 한다.
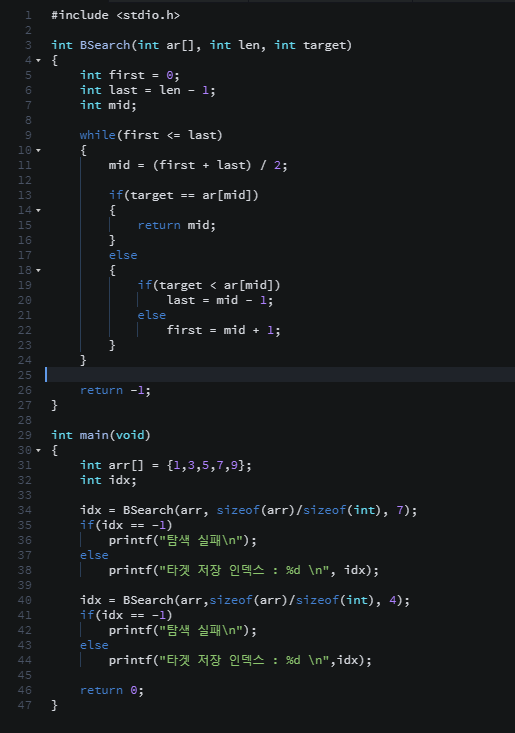
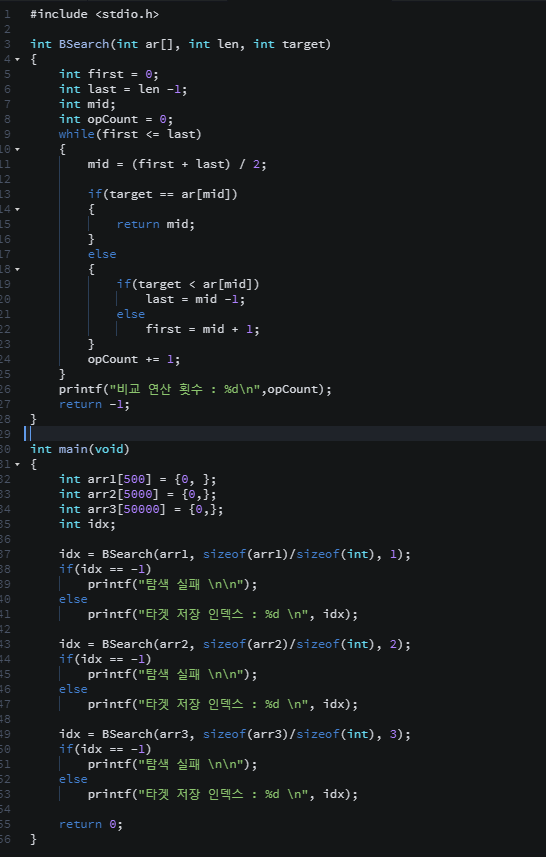
LinearSearch.c
탐색 알고리즘에서는 == 연산을 적게 수행하는 탐색 알고리즘이 좋은 탐색 알고리즘이다.
비교 연산의 수행횟수가 줄어들면 < 연산과 ++ 연산의 수행횟수도 줄어들고, 비교연산의 수행횟수가 늘어나면 < 연산과 ++ 연산의 수행횟수도 늘어나기 때문에 다른 연산들은 == 연산에 의존적이다.
위 탐색 알고리즘은 == 연산의 횟수를 대상으로 시간 복잡도를 분석하면된다.
=> 알고리즘의 시간 복잡도를 계산하기 위해서는 핵심이 되는 연산이 무엇인지 잘 판단해야 한다.
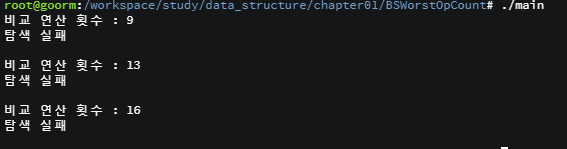
모든 알고리즘에는 가장 행복한 경우와 가장 우울한 경우가 각각 존재하며, 이를 '최선의 경우(best case)'와 '최악의 경우(worst case)'라 한다. 그러나 알고리즘을 평가하는데 있어서 '최선의 경우'는 관심 대상이 아니다. 알고리즘의 성능을 판단하는데 있어서 중요한 것은 '최악의 경우' 이다.