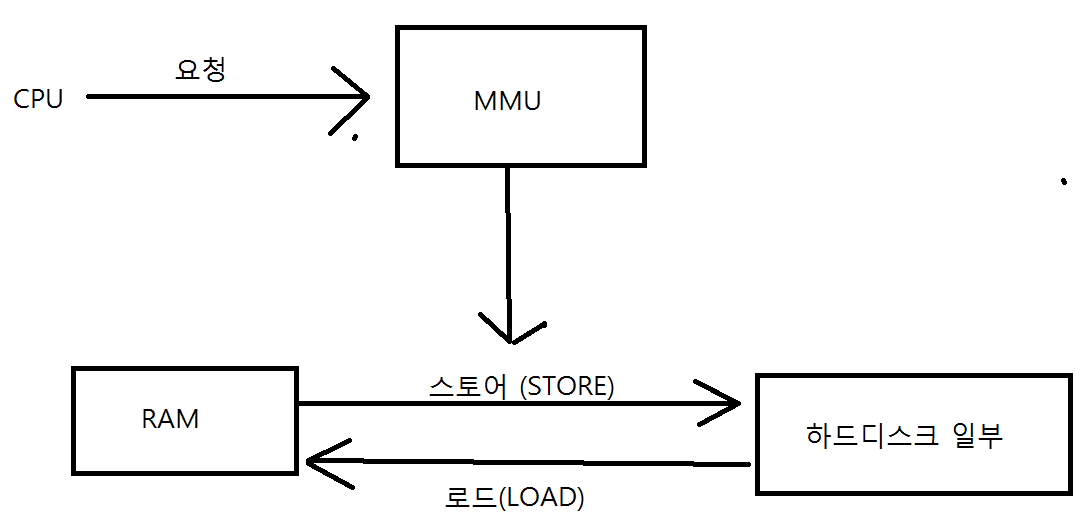
디렉터리 관련 함수 및 그밖의 함수들
디렉터리의 생성과 소멸
디렉터리 생성함수
BOOL CreateDirectory(
LPCTSTR lpPathName,
LPSECURITY_ATTRIBUTES lpSecurityAttributes
);
1.lpPathName : 생성하고자 하는 디렉터리 이름을 지정한다.
2.lpSecurityAttributes : 보안 속성을 지정할 때 사용된다. 기본적으로 NULL을 전달해서 디폴트 보안속성을 지정한다.
디렉터리 소멸함수
BOOL RemoveDirectory(
LPCTSTR lpPathName
);
1.소멸하고자 하는 디렉터리 이름 지정
CreateDirectory 첫번째 인자에 경로를 포함하지 않은 문자열만 전달할 시 해당 프로그램이 존재하는 곳에 디렉터리가 생성된다. 경로를 포함할 시 해당 경로에 디렉터리가 생성된다.
현재 디렉터리, 시스템 디렉터리, Windows디렉터리
현재 디렉터리(Current Directory)
현재 디렉터리는 프로그램이 존재하는 디렉터리이다.
초기에는 프로그램이 로드(Load)된 디렉터리로 설정되며, 이후 변경 가능하다.
->프로그램이 실행된 이후 현재 디렉터리는 언제든지 변경될 수 있다.
현재디렉터리 참조 함수
DWORD GetCurrentDirectory(
DWORD nBufferLength,
LPTSTR lpBuffer
);
1.nBufferLength : 두번째 인자로 전달된 버퍼의 길이를 지정한다.
2.pBuffer : 현재 디렉터리 정보를 저장할 버퍼의 주소값을 지정한다.
현재 디렉터리 변경함수
BOOL SetCurrentDirectory(
LPCTSTR lpPathName
);
1.lpPathName : 변경하고자 하는 현재 디렉터리 정보를 지정한다.
시스템 디렉터리(System Directory) & Windows 디렉터리
시스템 디렉터리는 각종 라이브러리(DLL) 및 드라이버 파일처럼 Windows 시스템에 중요한 파일들이 존재하는 위치였고, Windows 디렉터리는 초기화 및 실행파일들이 존재하는 위치이다.
시스템 디렉터리와 Windows 디렉터리는 변경이 불가능 하며 변경해서는 안된다.
시스템 디렉터리 위치 정보 확인 함수
UINT GetSystemDirectory(
LPTSTR lpBuffer,
UINT uSize
);
1.lpBuffer : 시스템 디렉터리 정보를 저장할 버퍼의 주소값을 지정한다.
2.uSize : 첫번째 인자로 전달된 버퍼의 길이를 지정한다.
윈도우 디렉터리 위치 정보 확인 함수
UINT GetWindowsDirectory(
LPTSTR lpBuffer,
UINT uSize
);
1.lpBuffer : Windows 디렉터리 정보를 저장할 버퍼의 주소값을 지정한다.
2.uSize : 첫번째 인자로 전달된 버퍼의 길이를 지정한다.
windef.h에 MAX_PATH가 정의되어있다. 이는 디폴트 최대경로 길이 248을 고려하여 선언된 매크로 상수이다. 따라서 파일이름(완전 경로를 포함하는)을 저장하기 위한 문자열 버퍼를 선언할 때 활용할 수 있다.
#define MAX_PATH 260
디렉터리에서 파일 찾기
파일의 위치정보나 특정 디렉터리 내에 존재하는 파일 정보를 얻고자 할 때 사용할 수 있는 함수들
SearchPath 함수는 문자열로 지정한 경로에 특정 파일이 존재하는지 확인하는 용도로 사용할 수 있다. 파일 이름을 인자로 하여 해당 파일이 저장되어 있는 완전경로를 얻고자 할 때에 사용할 수 있다.
DWORD SearchPath(
LPCTSTR lpPath,
LPCTSTR lpFileName,
LPCTSTR lpExtension,
DWORD nBufferLength,
LPCTSTR lpBuffer,
LPCTSTR* lpFilePart
);
1.lpPath : 대상 경로를 지정한다. 이 인자를 통해서 지정된 경로에서 파일을 찾게 된다. 인자로 NULL이 전달되면, 다음과 같은 순서로 파일을 찾게된다. 아래의 경로를 가리켜 표준 검색 경로라 한다.
1_실행 중인 프로그램이 로드(Load)된 디렉터리(실행 파일이 존재하는 디렉터리)
2_현재 디렉터리(Current Directory)
3_시스템 디렉터리(System Directory)
4_Windows 디렉터리
5_마지막으로 환경변수 PATH에 등록된 디렉터리
2.lpFileName : 찾고자 하는 파일 이름
3.lpExtension : 확장자를 지정하는 인자로서 첫번째 문자는 반드시 '.'으로 시작해야 한다. lpFileNAme이 확장자를 포함하고 있거나 확장자를 지정해 줄 필요가 없을 때에는 NULL을 지정한다.
4.nBufferLength : 완전 경로명을 저장할 버퍼의 길이를 요구한다.
5.lpBuffer : 완전 경로명을 저장할 버퍼의 주소를 지정한다.
6.lpFilePart : 함수 호출 결과로 얻게되는 완전경로 명(lpBuffer로 지정된 버퍼에 저장되는 완전경로명)의 마지막에는 파일 이름도 추가된다. 이 전달인자를 통해서 파일 이름이 저장된 위치 정보(포인터 값)를 얻게된다.
FindFirstFile 함수
HANDLE FindFirstFile(
LPCTSTR lpFileName,
LPWIN32_FIND_DATA lpFindFileData
);
1.lpFileName : 파일이나 디렉터리 이름 지정. 지정된 정보를 근거로 파일(혹은 디렉터리)정보를 얻게된다.
2.lpFindFileData : 발견된 파일이나 디렉터리 정보를 담을 WIN32_FIND_DATA 구조체 변수의 주소값을 전달한다.
FindFirstFile 함수의 반환 타입이 HANDLE이다. FindFirstFile 함수를 통해서 조건에 맞는 파일 중 가장 첫번째 검색된 파일 정보만 얻을 수 있다.
FindNextFile 함수
BOOL FindNextFile(
HANDLE hFindFile,
LPWIN32_FIND_DATA lpFindFileData
);
1.hFindFile : FindFirstFile 함수 호출을 통해서 얻은 핸들을 전달한다.
2.lpFindFileData : 발견된 파일이나 디렉터리의 정보를 담을 WIN32_FIND_DATA구조체 변수의 주소값을 전달한다.
BOOL FindClose(
HANDLE hFindFile
);
1.hFindFile : FindFirstFile 함수를 통해서 얻은 핸들을 반환한다.
FindFirstFile 함수와 FindNextFile함수의 사용법은 LinkedList의 LFirst와 LNext함수 사용법과 유사하다.
FindFirstFile을 통해 조건에 부합하는 첫번째 파일에 대한 파일 정보를 두번째 인자에 저장한다.
이후 FindNextFile에 FindFirstFile함수 반환 핸들을 인자로 넣어 조건에 부합하는 다음 파일에 대한 정보를 받아온다.
이후 FindClose함수를 통해 FindFirstFile 함수 반환 핸들을 반환해 준다.
'Programming > Windows System Programming' 카테고리의 다른 글
| 파일 I/O 와 디렉터리 컨트롤(2) (0) | 2020.08.19 |
|---|---|
| 파일 I/O 와 디렉터리 컨트롤(1) (0) | 2020.08.16 |
| SEH(Structured Exception Handling) (0) | 2020.08.10 |
| 가상 메모리(Virtual Memory) (0) | 2020.08.08 |
| 캐쉬(cache)와 캐쉬 알고리즘 (0) | 2020.08.07 |