힙, 데이터 영역, 그리고 코드영역의 공유에 대한 검증
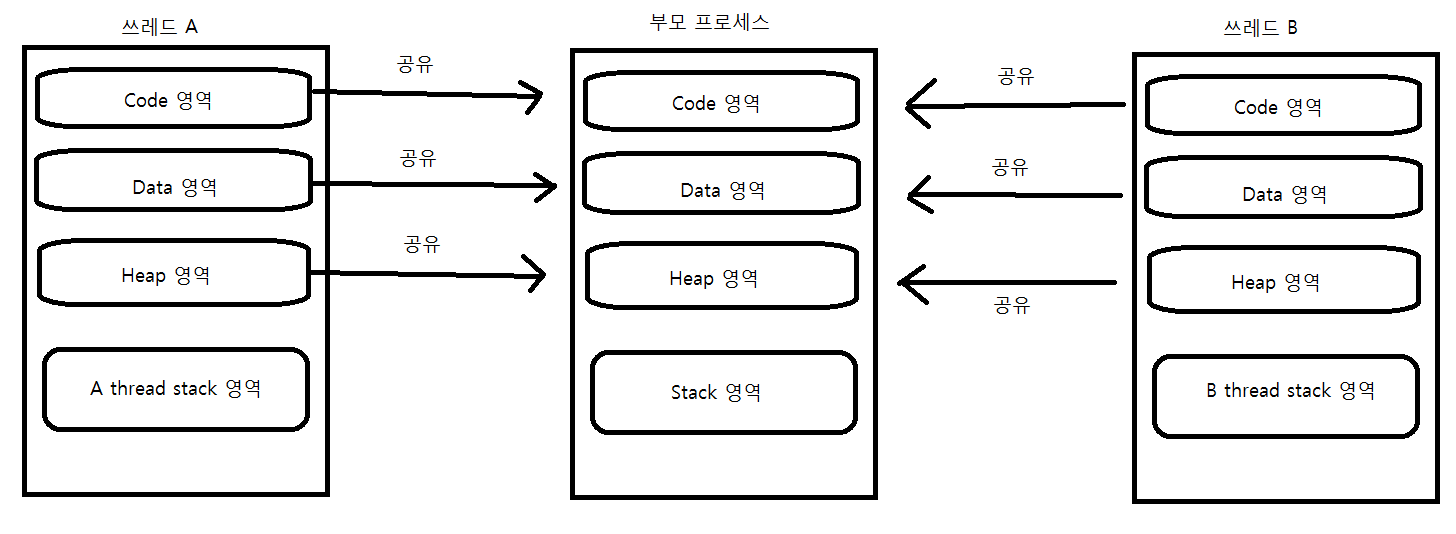
쓰레드는 메모리를 공유한다. 특히 전역변수가 할당되는 데이터 영역과, 메모리가 동적으로 할당되는 힙영역을 공유한다.
메모리 동시접근 문제
전역변수에 둘 이상의 쓰레드가 동시 접근을 할 수 있다.
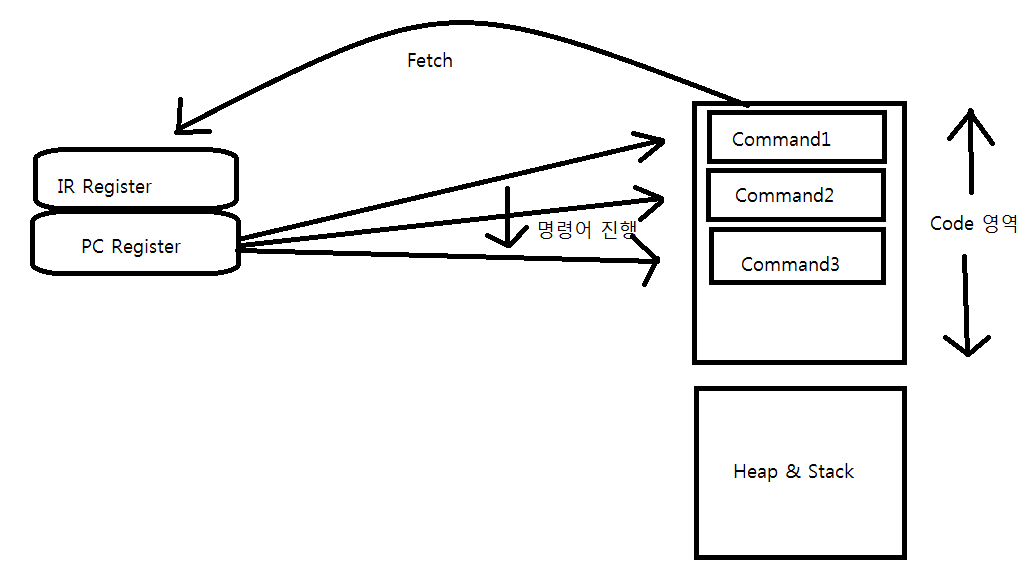
실제로는 쓰레드는 돌아가면서 실행된다. 전역변수에 접근하여 연산을 하기 위해서는 메모리에 저장된 데이터를 레지스터로 이동시켜야한다. 이후 ALU에 의해 실질적인 덧셈 연산이 진행되고, 그 결과가 다시 메모리에 저장되는 구조로 진행이딘다. 여러 쓰레드에서 하나의 전역변수를 연산에 사용할 때는 실행중인 쓰레드의 변경에 의해서 컨텍스트 스위칭이 빈번하게 발생한다. 때문에 둘 이상의 쓰레드가 같은 메모리 영역을 동시에 참조하는 것은 문제를 일으킬 가능성이 매우 높다.
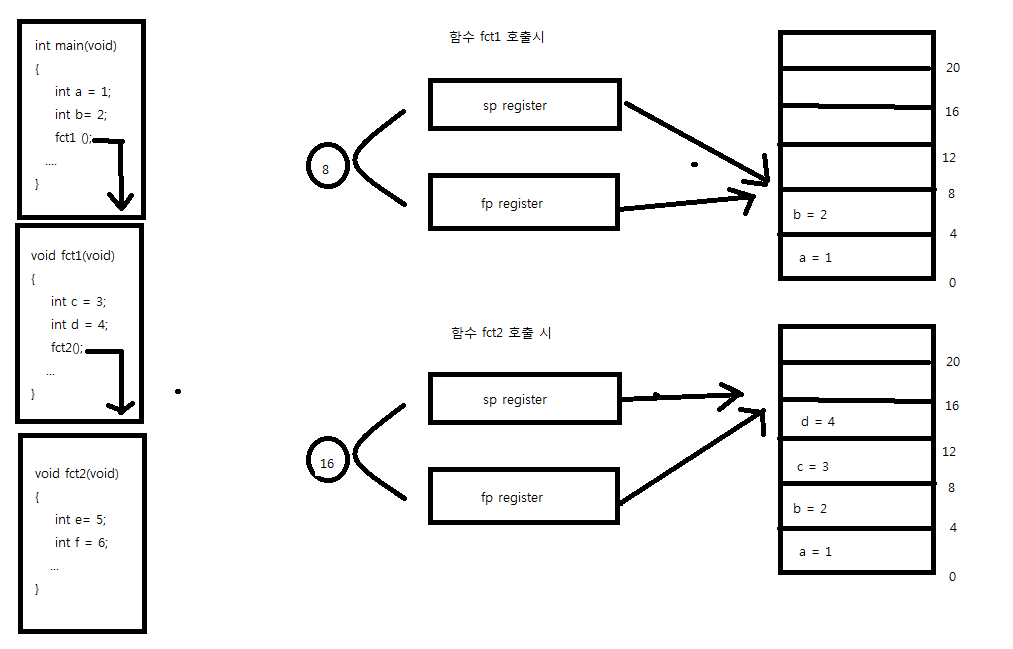
프로세스로 부터의 쓰레드 분리
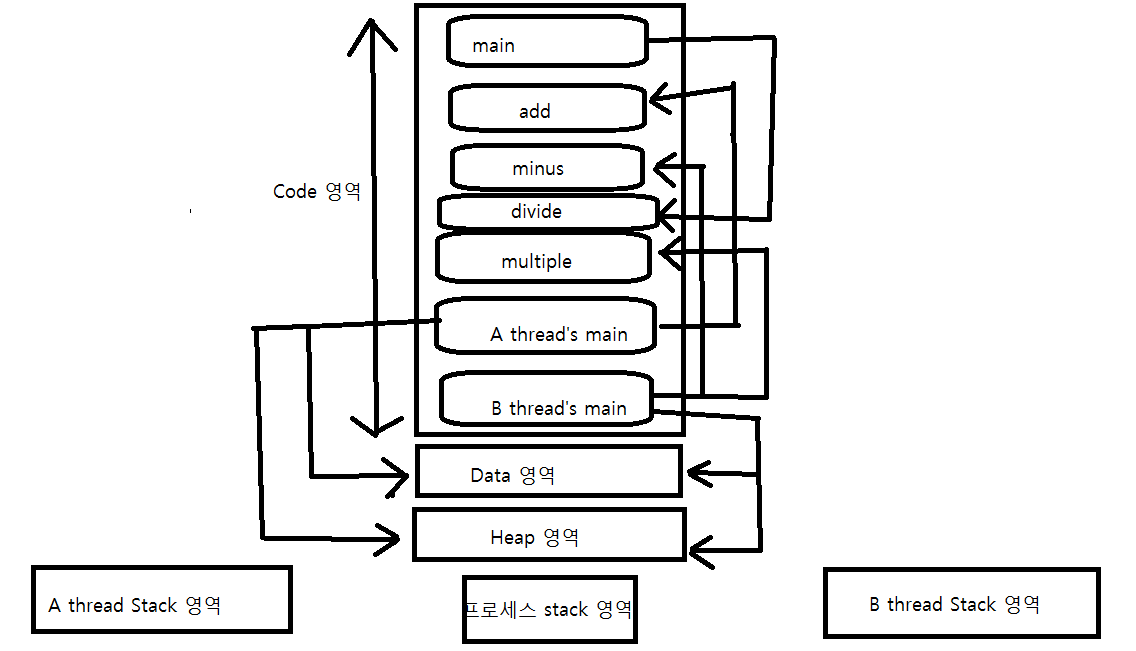
프로세스는 쓰레드를 담는 상자역할을 한다. 그리고 핸들 테이블 또한 프로세스 소유이다. 즉 하나의 프로세스에 하나의 핸들 테이블이 존재한다. 또한 같은 프로세스 내에서 생성된 모든 쓰레드들은 스택 이외의 모든것을 공유하기 때문에 핸들 테이블도 공유한다.
ANSI 표준 C 라이브러리와 쓰레드
멀티 쓰레드 기반 라이브러리를 설정하고 쓰레드를 생성할 때, CreateTread함수가 아니라 _beginthreadex 함수를 사용해야 한다. _beginthreadex 함수도 내부적으로는 쓰레드 생성을 위해서 CreateThread함수를 호출 한다. 다만 쓰레드를 생성하기에 앞서서 쓰레드를 위해, 독립적인 메모리 블록을 할당해준다는 차이점이 있다. 각각의 메모리 블록을 할당 함으로써 멀티쓰레드의 안정성이 확보된다.
_beginthreadex 함수
uintptr_t _beginthreadex(
void * security,
unsigned stack_size,
unsigned (*start_address)(void *),
void * arglist,
unsigned initflag,
unsigned *thrdaddr
);
함수의 전달인자의 순서와 의미는 CreateThread함수와 동일하다. 다만 매개변수 자료형과 반환형에 차이가 있어, 약간의 형 변환이 요구된다.
_beginthreadex 함수를 사용하기 위해서는 헤더파일 process.h를 추가로 포함시켜야 한다.
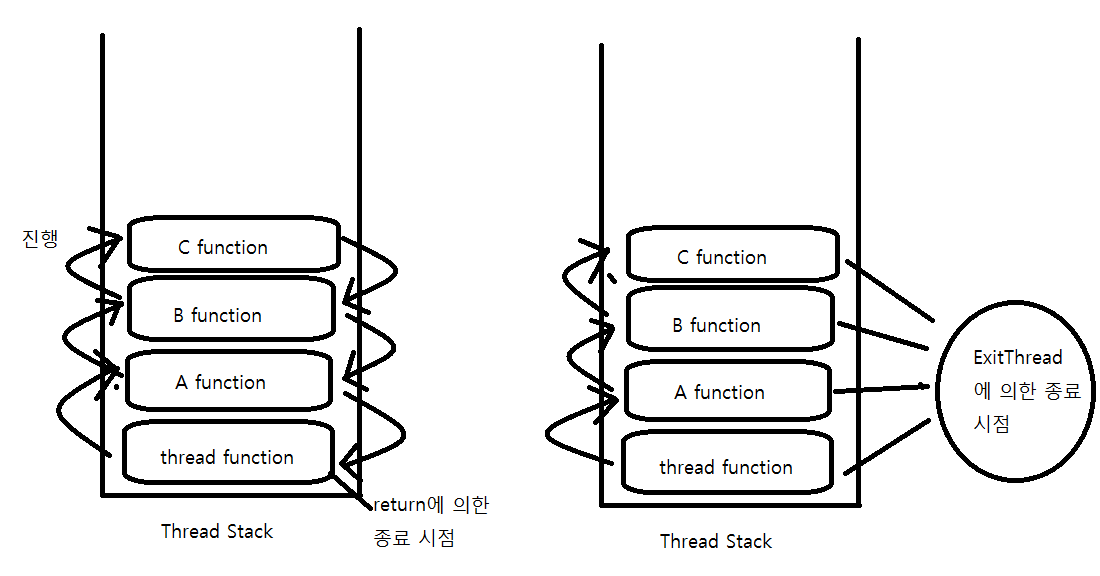
_beginthradex 함수를 종료할 때 가장 좋은 방법은 return문을 이용하는 것이다.
ExitThread 함수를 활용해야할 상황이라면 _endthreadex(unsigned retval);를 사용하는 것이 좋다. _endthreadex이 함수는 내부적으로 쓰레드에 할당된 메모리를 해제하고 ExitThread함수를 호출한다. 쓰레드 함수에서 return 문을 이용하더라도 _endthreadex함수가 자동으로 호출된다.
'Programming > Windows System Programming' 카테고리의 다른 글
| 쓰레드 동기화 (0) | 2020.07.28 |
|---|---|
| 쓰레드 상태 컨트롤 (0) | 2020.07.26 |
| Windows에서의 쓰레드 생성과 소멸 (0) | 2020.07.23 |
| 쓰레드 구현 모델에 따른 구분 (0) | 2020.07.22 |
| 쓰레드의 이해 (0) | 2020.07.20 |