collect()
collect()는 스트림의 요소를 수집하는 최종연산이다.
collect에는 어떻게 수집할 것인가에 대한 방법이 필요하는데 이러한 방법을 정의한것이 컬렉터(collector)이다.
컬렉터는 Collector 인터페이스를 구현한 것으로, 직접 구현하거나 미리 작성된 것을 사용할 수 있다.
Collectors클래스는 미리 작성된 다양한 컬렉터를 반환하는 static메서드를 가지고 있다.
스트림의 요소를 수집하는 collect()의 매개변수로는 수집하는 방법인 컬렉터가 사용된다.
해당 컬렉터는 Collector 인터페이스를 통해 구현하거나, Collectors클래스의 static메서드를 통해 얻을 수 있다.
collect() : 스트림의 최종연산, 매개변수로 컬렉터가 필요하다.
Collector : 인터페이스로 컬렉터를 구현할 때 사용한다.
Collectors : 클래스이다. 미리작성된 static메서드로 컬렉터를 제공한다.
collect() 선언
Object collect(Collector collector) //Collector인터페이스를 구현한 객체를 매개변수로 사용한다.
Object collect(Supplier supplier, BiConsumer accumulator, BiConsumer combiner)
스트림을 컬렉션과 배열로 변환 - toList(), toSet(), toMap(), toCollection(), toArray()
스트림의 모든 요소들을 컬렉션에 수집하기 위한 메서드들이다.
List<String> names = stuStream.map(Student::getName).collect(Collectors.toList());
Student스트림의 모든 요소들의 이름을 List로 수집한 코드이다.
ArrayList<String> list = names.stream().collect(Collectors.toCollection(ArrayList::new));
List<String>을 ArrayList로 할당한 코드이다.
List나 Set은 toList(), toSet()이 있지만 다른 컬렉션을 사용하고 싶은 경우 Collectors의 toCollection()에 해당 컬렉션 생성자를 넣어주면 가능하다.
toMap()
Map<String, Person> map = personStream.collect(Collectors.toMap(p->p.getRegId(), p->p));
toMap의 경우 key와 value를 각각 지정해 주어야한다.
스트림에 지정된 요소들을 배열로 저장하는 메서드 toArray()
toArray()에 매개변수로 해당 타입의 생성자 참조를 넣어주어야한다. 매개변수를 작성하지 않을시 반환되는 배열의 타입은 Object[] 이다.
Student[] stuNames = studentStream.toArray(Student[]::new);
Object[] stuNames = studentStream.toArray();
통계 - counting(), summingInt(), averagingInt(), maxBy(), minBy()
개수, 합, 평균, 최대값, 최솟값등을 반환하는 메서드이다.
ex)
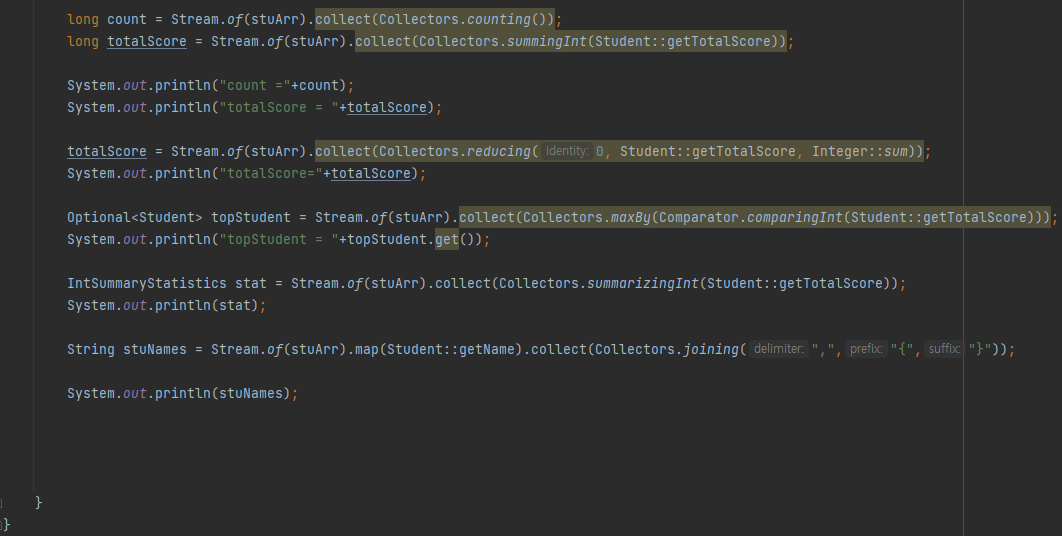
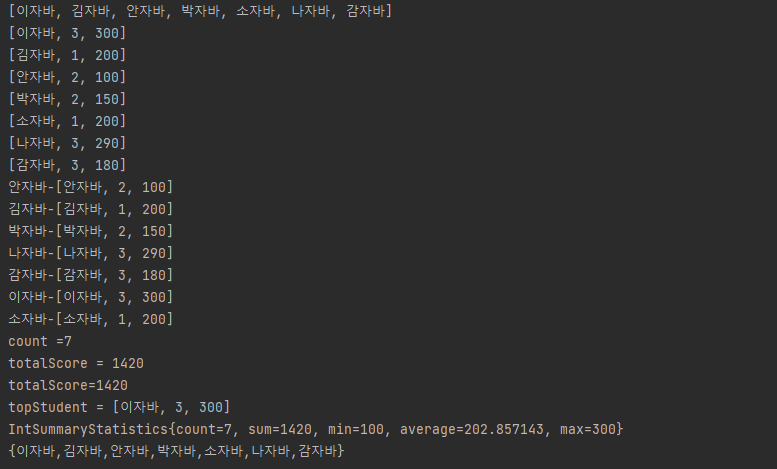
long count = stuStream.count();
long count = stuStream.collect(Collectors.counting());
long totalScore = stuStream.mapToInt(Student::getTotalScore).sum();
long totalScore = stuStream.collect(summingInt(Student::getTotalScore));
OptionalInt topScore = studentStream.mapToInt(Student::getTotalScore).max();
Optional<Student> topStudent = stuStream.max(Comparator.comparingInt(Student::getTotalScore));
Optional<Student> topStudent = stuStream.collect(maxBy(Comparator.comparingInt(Student::getTotalScore));
IntSummaryStatics stat = stuStream.mapToInt(Student::getTotalScore).summaryStatistics();
IntSummaryStatics stat = stuStream.collect(summarizingInt(Student::getTotalScore));
위 예시는 collect를 사용한경우와 사용하지않은 경우를 비교한 것이다. collect사용법으로 알아두면 좋을것 같다.
리듀싱 - reducing()
리듀싱 선언
Collector reducing(BinaryOperator<T> op)
Collector reducing(T identity, BinaryOperator<T> op)
Collector reducing(U identity, Function<T, U> mapper, BinaryOperator<U> op)
사용예시
IntStream intStream = new Random().ints(1,46).distinct().limit(6);
OptionalInt max = intStream.reduce(Integer::max);
Optional<Integer> max = intStream.boxed().collect(reducing(Intger::max));
//intStream을 boxed()를 통해 Stream<Integer>로 변경한다.그래야 Stream에 선언된 collect를 사용할 수 있다.
long sum = intStream.reduce(0, (a,b) -> a+b);
long sum = intStream.boxed().collect(reducing(0,(a,b)->a+b));
int grandTotal = stuStream.map(Student::getTotalScore).reduce(0, Integer::sum);
int grandTotal = stuStream.collect(reducing(0, Student::getTotalScore, Integer::sum));
문자열 결합 - joining()
스트림의 모든요소를 하나의 문자열로 결합하여 반환한다. 구분자 지정및 접두사, 접미사 지정도 가능하다.
스트림의 요소가 문자열이 아닌경우에는 map()을 통해 문자열로 변환해주어야한다.
ex))
String studentNames = stuStream.map(Student::getName).collect(joining());
String studentNames = stuStream.map(Student::getName).collect(joining(","));
String studentNames = stuStream.map(Studednt::getName).collect(joining(",","[","]");


'Programming > JAVA' 카테고리의 다른 글
| 자바의 입출력 (0) | 2021.09.10 |
|---|---|
| 그룹화와 분할 - groupingBy(), partitioningBy() (0) | 2021.09.02 |
| 스트림의 최종연산 (0) | 2021.09.01 |
| Optional (0) | 2021.08.25 |
| 스트림(Stream)의 중간연산 (0) | 2021.08.25 |