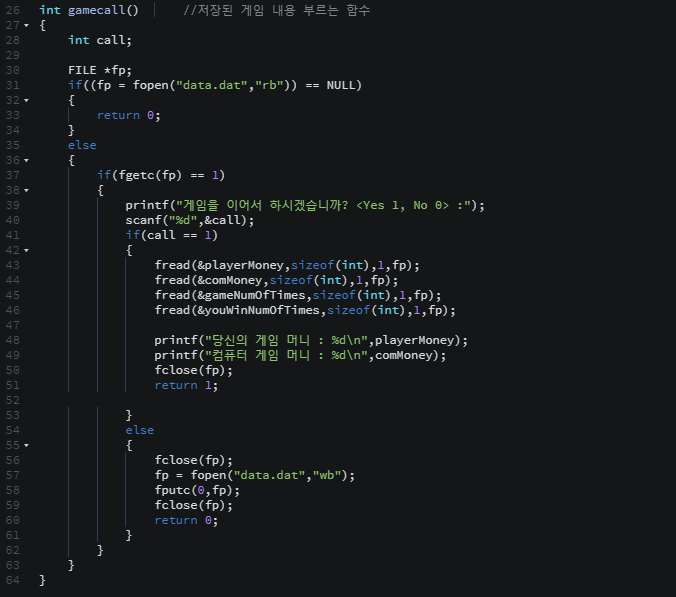
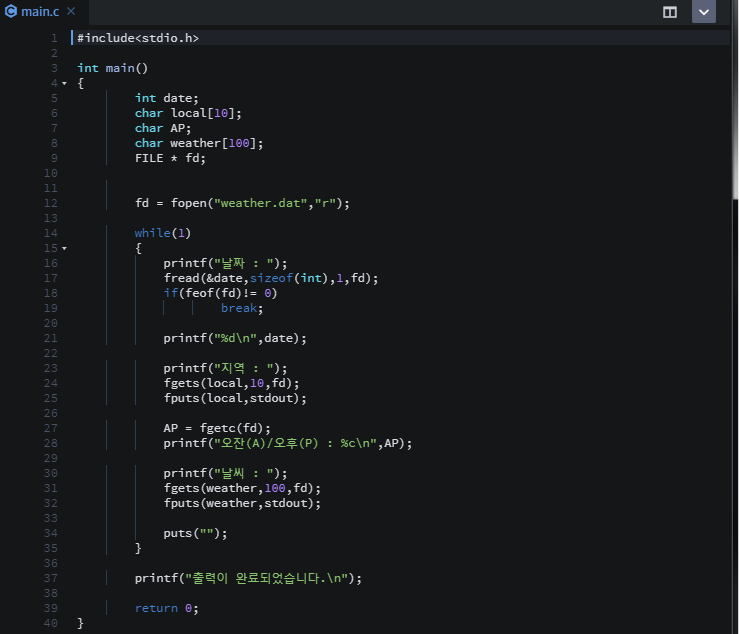
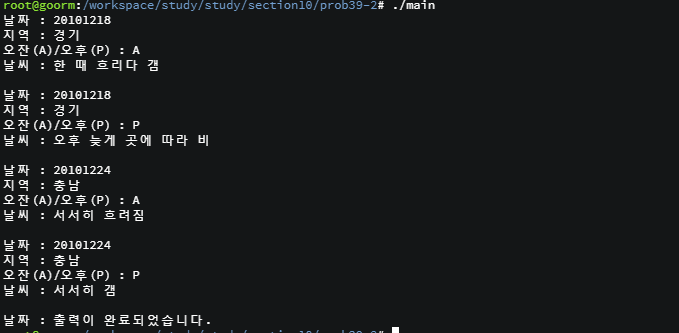
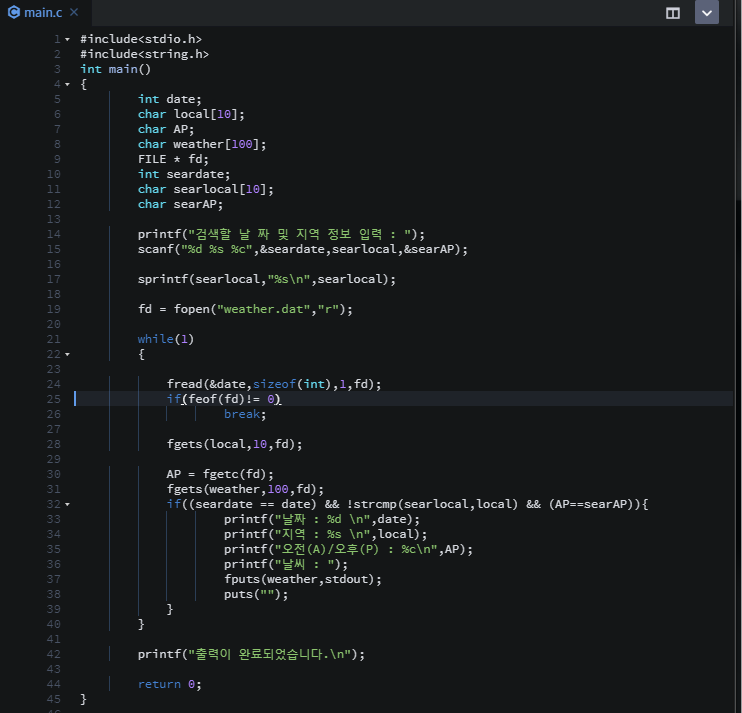
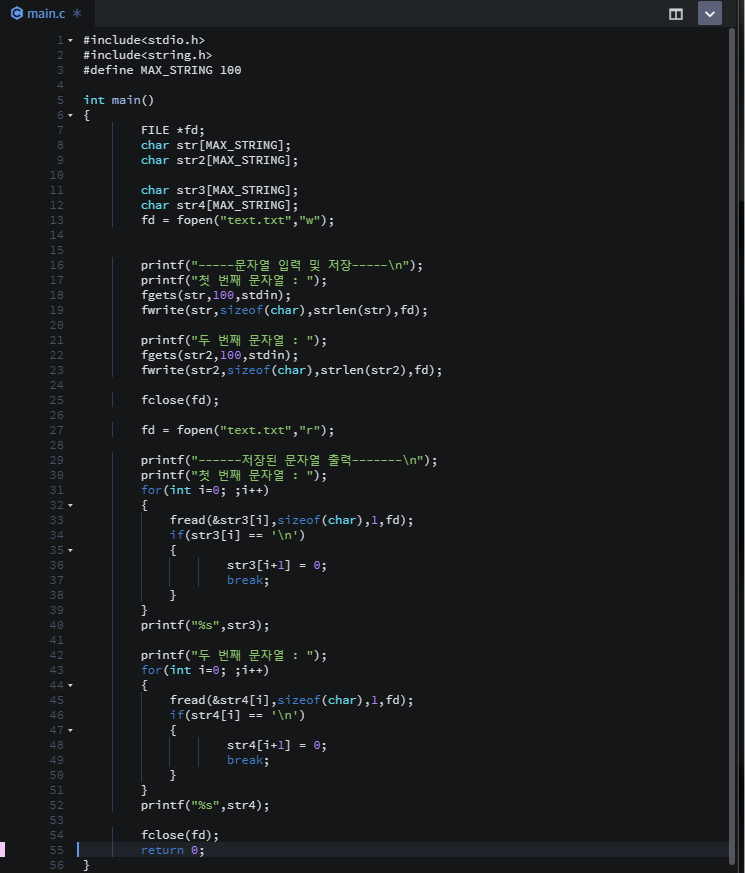
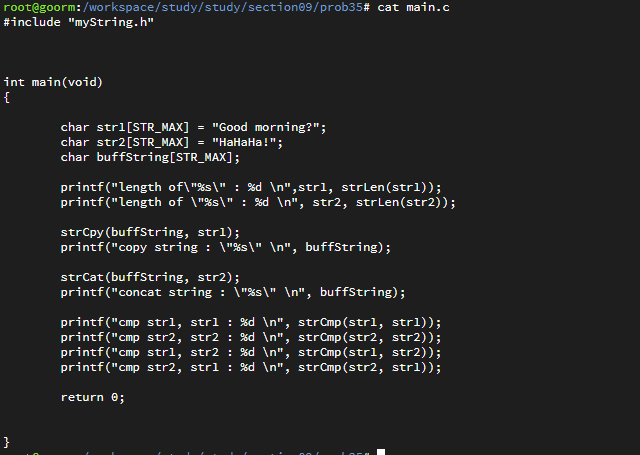
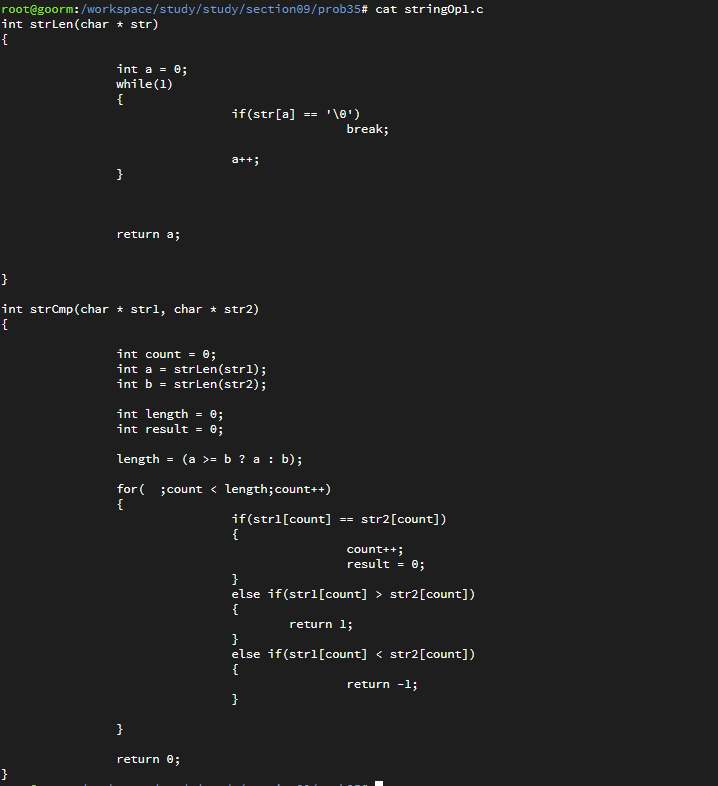
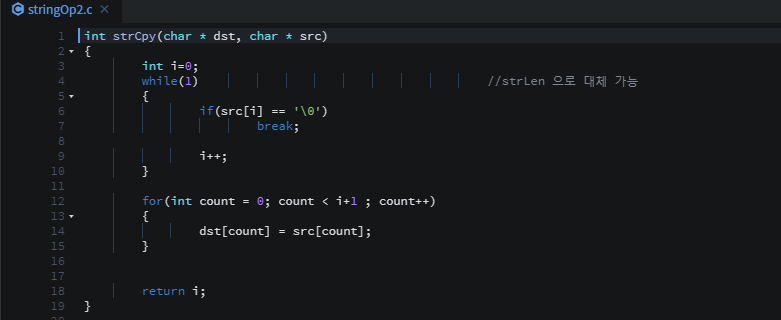
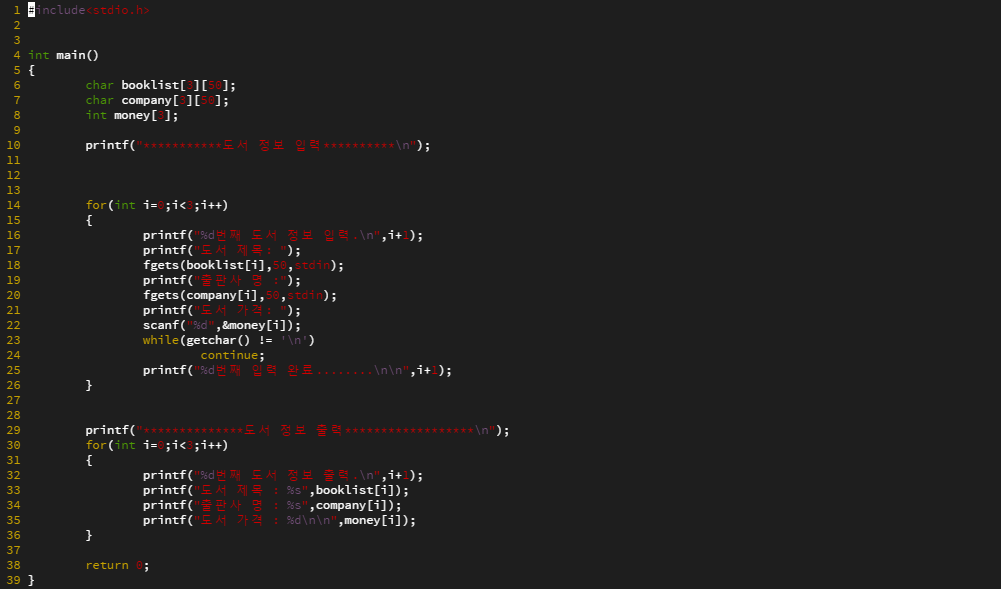
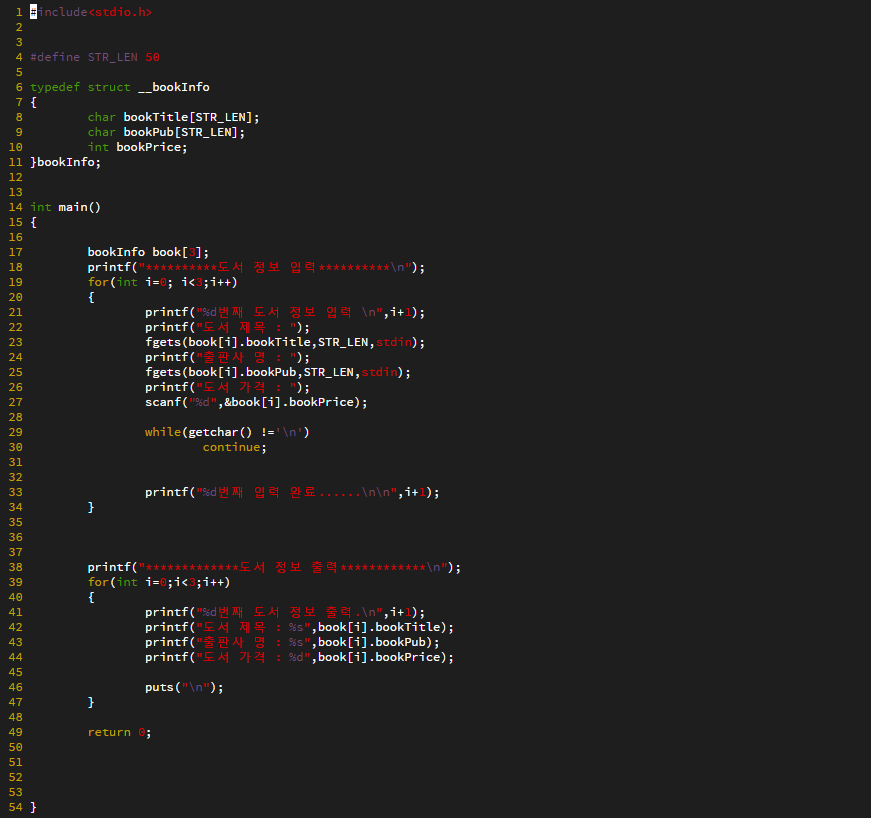
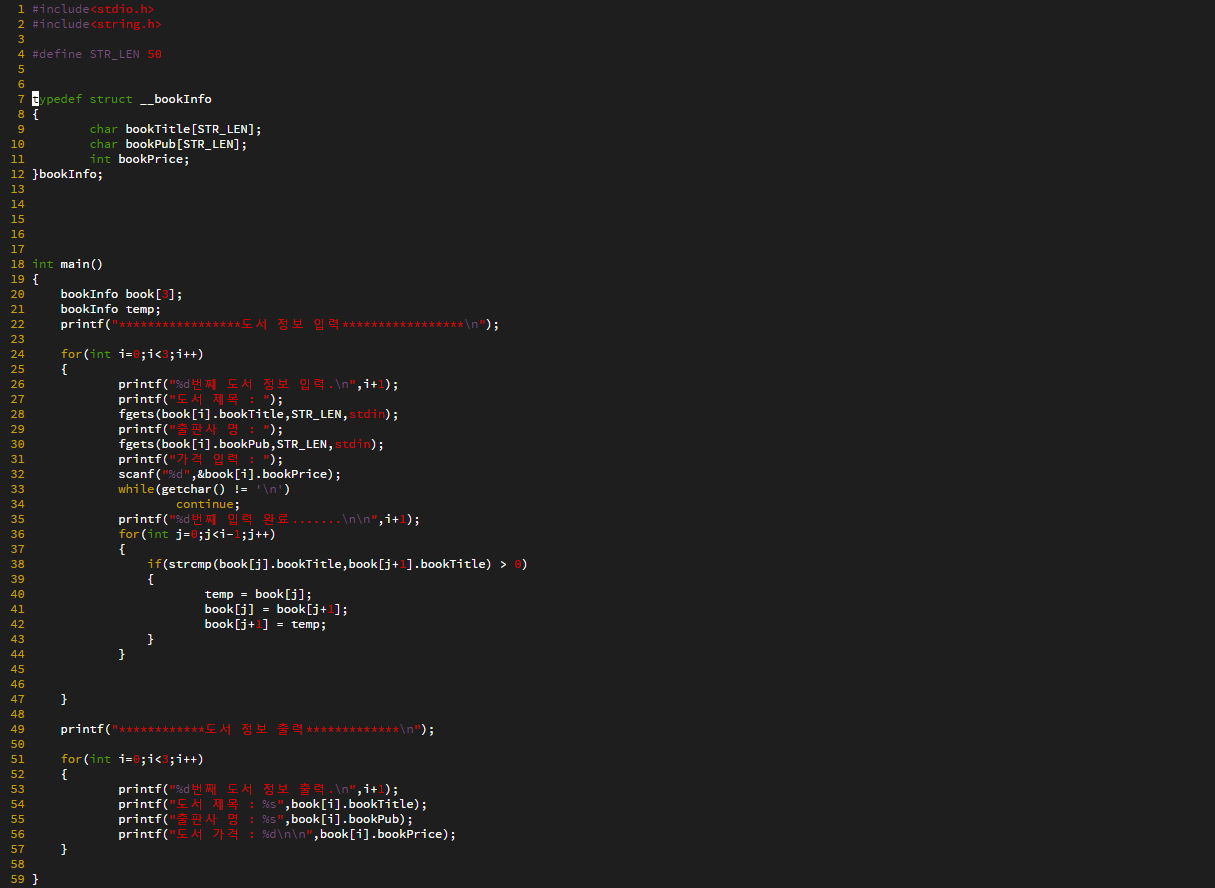
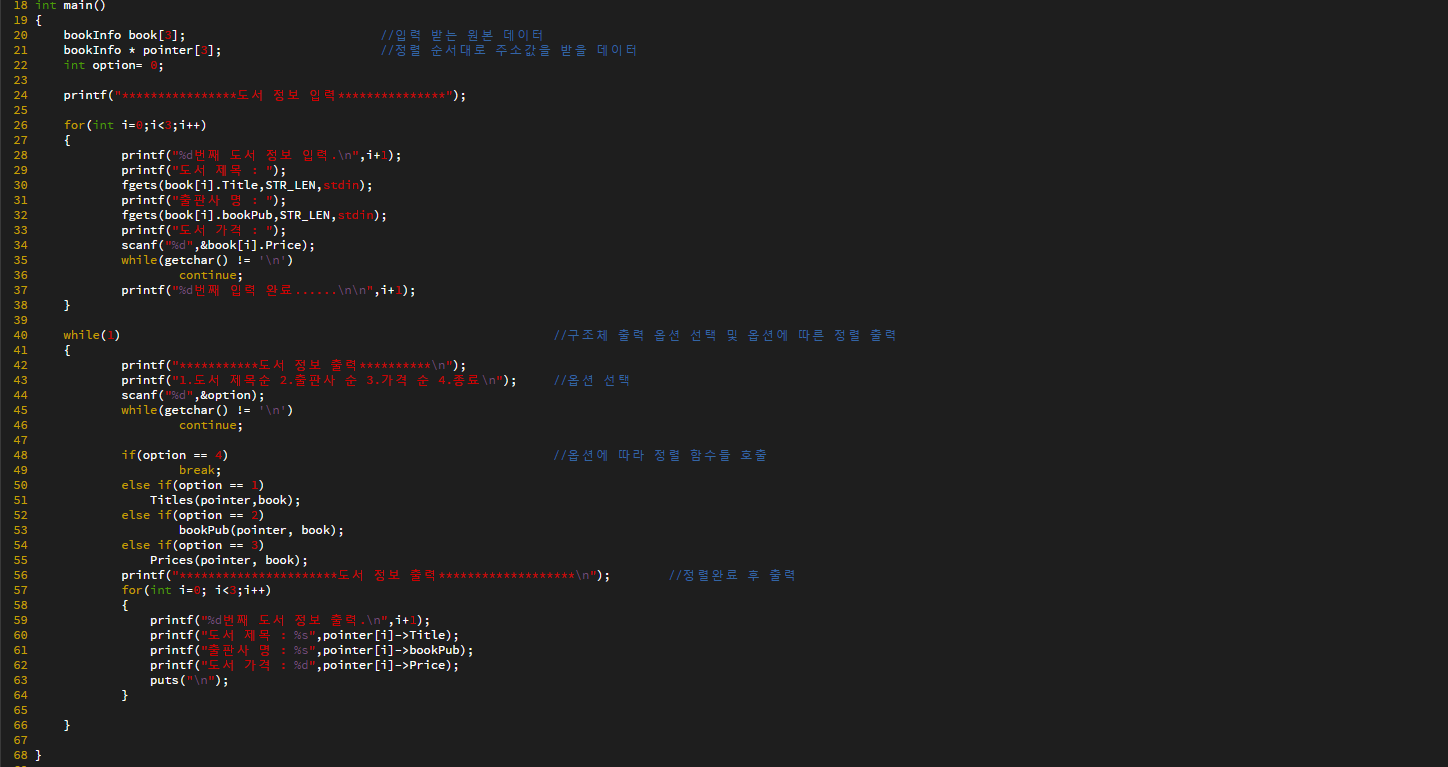
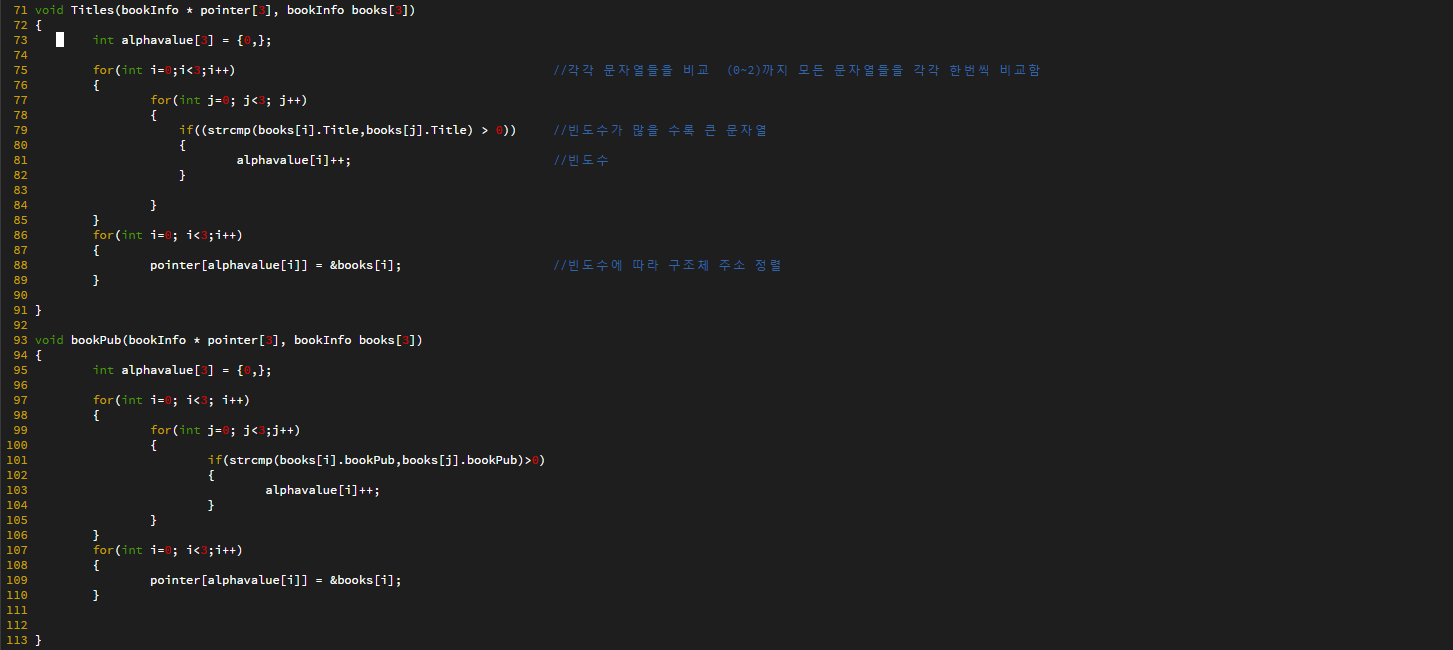
자료구조 : 데이터의 표현 및 저장 방법
자료구조의 분류

선형 구조 : 데이터를 선의 형태로 나란히 혹은 일렬로 저장하는 방식
비선형 구조 : 데이터를 나란히 저장하지 않는 구조
자료구조와 알고리즘
자료구조가 '데이터의 표현 및 저장 방법' 이라면, 알고리즘은 표현 및 저장된 데이터를 대상으로 하는 '문제 해결 방법'이다.
-> 자료구조가 결정되면 그에 따른 효율적인 알고리즘을 결정할 수 있다.
알고리즘은 자료구조에 의존적이다.
알고리즘 성능 분석 방법
잘 동작하고 좋은 성능을 보장받기를 원한다면 자료구조와 알고리즘을 분석하고 평가할 수 있어야 한다.
자료구조와 알고리즘을 평가하는 두가지 요소는 '속도'와 '메모리 사용량' 이다.
속도에 해당하는 수행시간 분석결과를 '시간 복잡도(time complexity)' 라고 하고, 메모리 사용량에 대한 분석 결과를 '공간 복잡도(space complexity)'라고 한다.
알고리즘 수행 속도 평가 방식
1.연산의 횟수
2.데이터의 수 n에 대한 연산횟수 T(n) 구성.
함수 T(n)을 구성하면 데이터 수의 변화에 따른 연산 횟수 변화를 한눈에 파악할 수 있어, 둘 이상의 알고리즘을 비교하기 용이해진다.
데이터 수에 따라 연산횟수도 달라지기 때문에 상황에 맞는 알고리즘을 찾아야 한다.
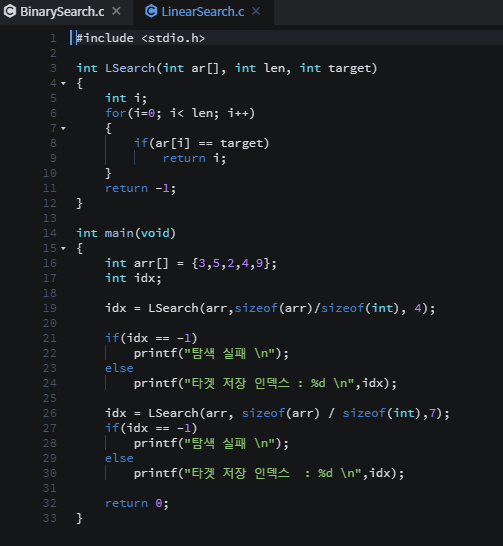
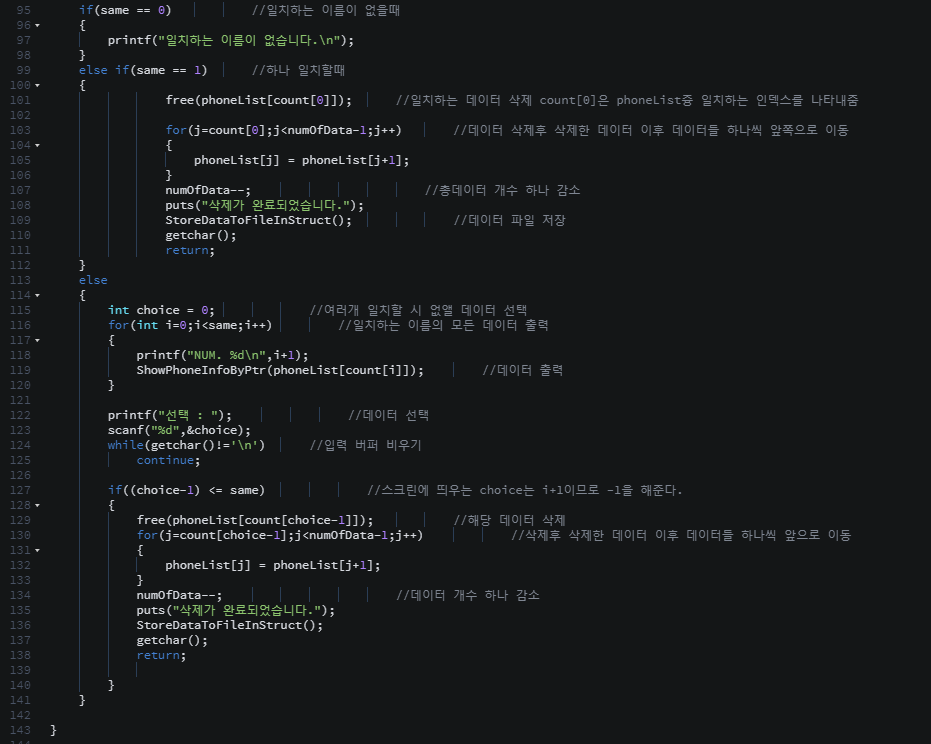
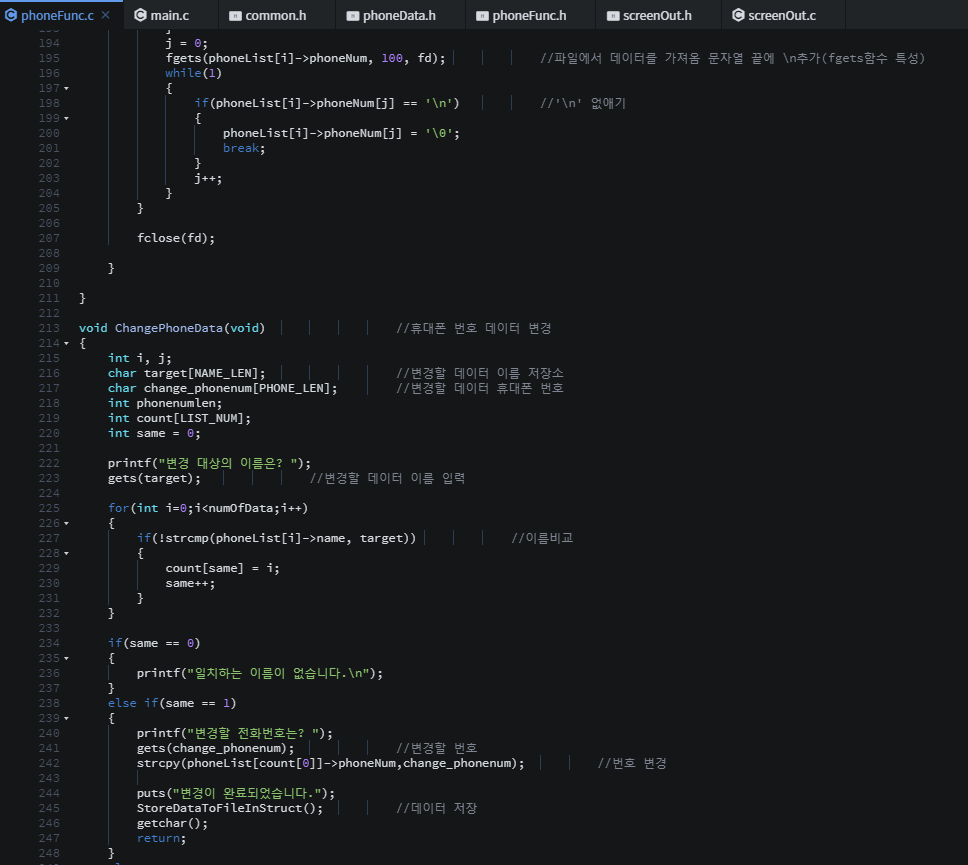
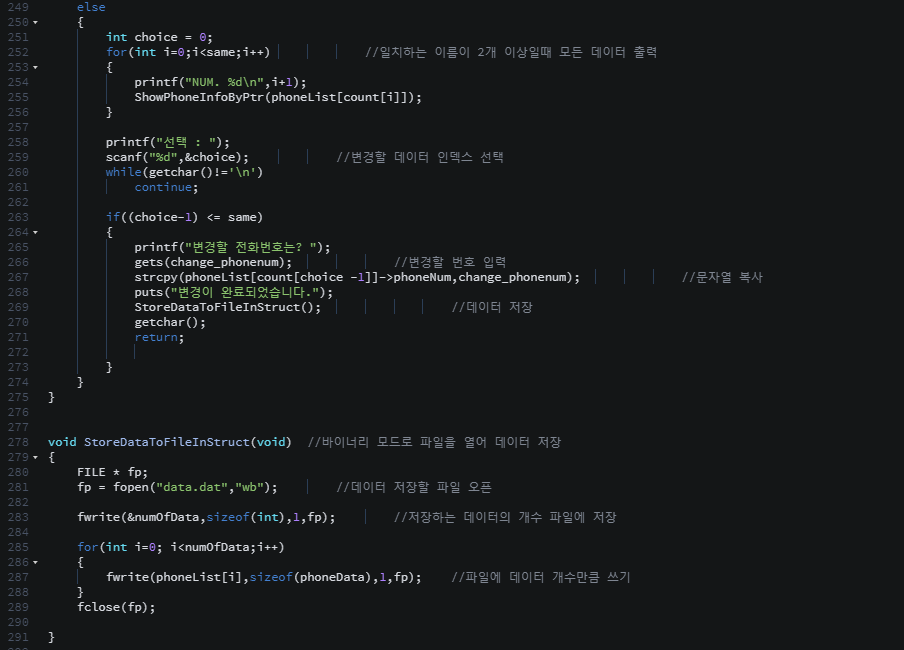
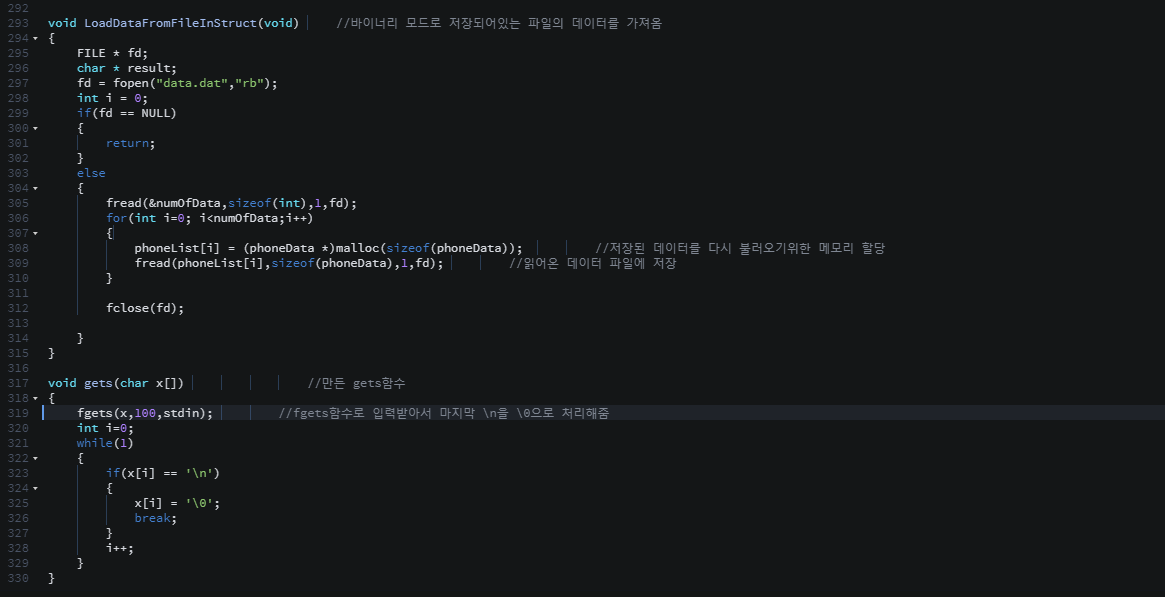
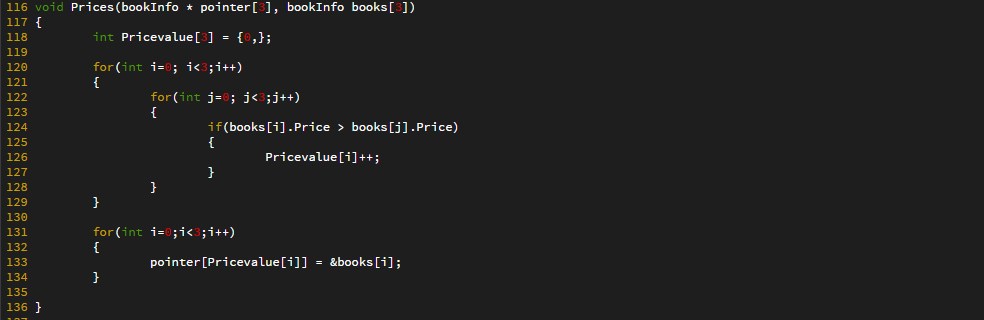
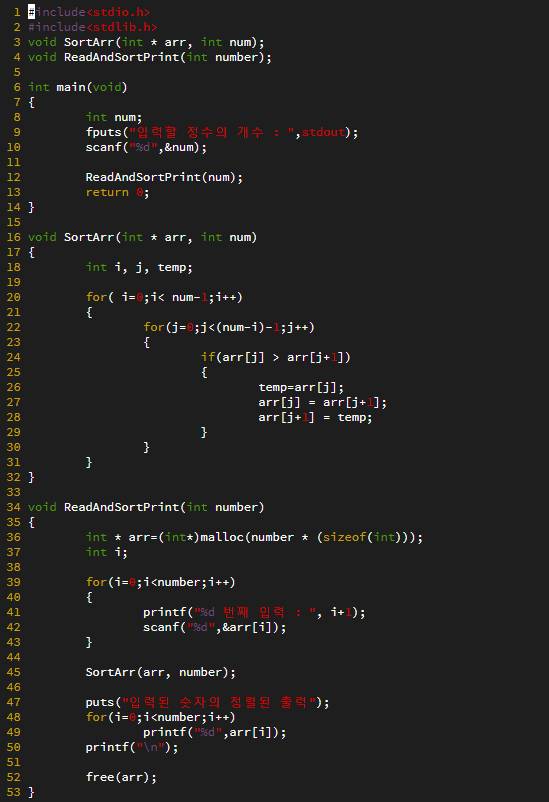
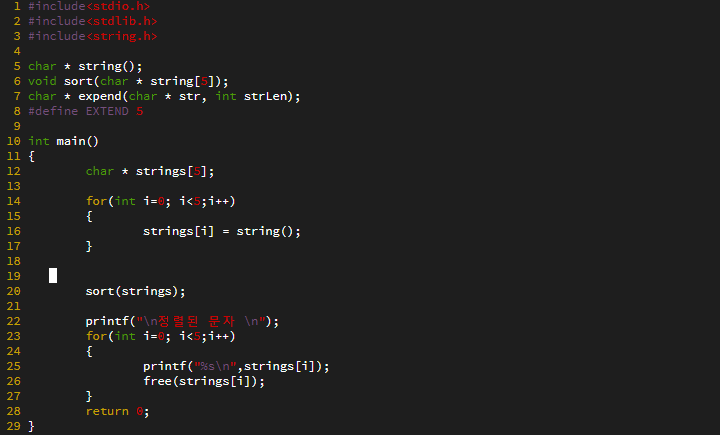
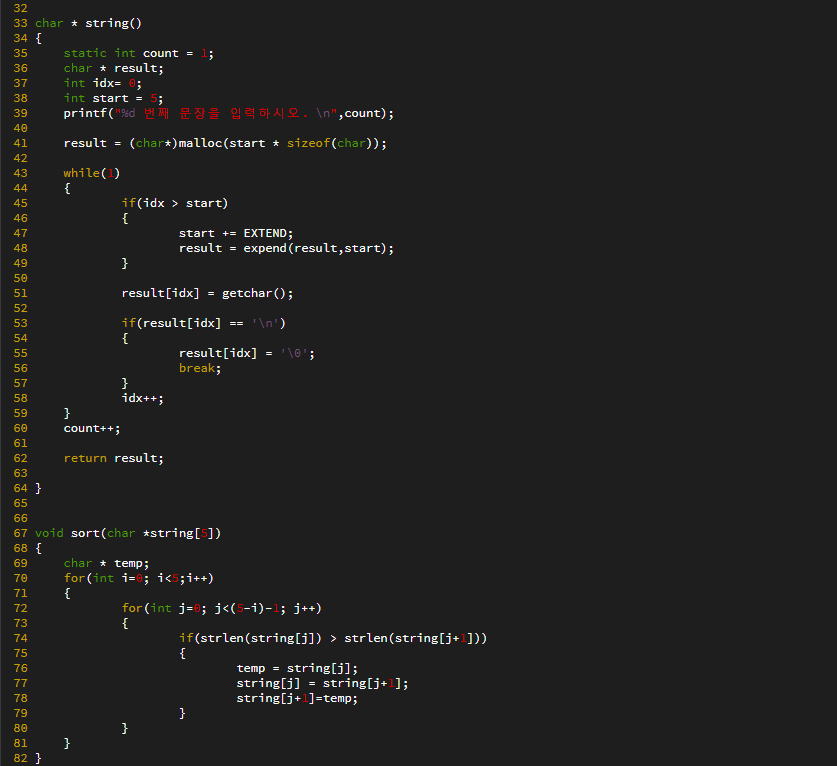
탐색 알고리즘에서는 == 연산을 적게 수행하는 탐색 알고리즘이 좋은 탐색 알고리즘이다.
비교 연산의 수행횟수가 줄어들면 < 연산과 ++ 연산의 수행횟수도 줄어들고, 비교연산의 수행횟수가 늘어나면 < 연산과 ++ 연산의 수행횟수도 늘어나기 때문에 다른 연산들은 == 연산에 의존적이다.
위 탐색 알고리즘은 == 연산의 횟수를 대상으로 시간 복잡도를 분석하면된다.
=> 알고리즘의 시간 복잡도를 계산하기 위해서는 핵심이 되는 연산이 무엇인지 잘 판단해야 한다.
모든 알고리즘에는 가장 행복한 경우와 가장 우울한 경우가 각각 존재하며, 이를 '최선의 경우(best case)'와 '최악의 경우(worst case)'라 한다. 그러나 알고리즘을 평가하는데 있어서 '최선의 경우'는 관심 대상이 아니다. 알고리즘의 성능을 판단하는데 있어서 중요한 것은 '최악의 경우' 이다.
'Programming > C 자료구조' 카테고리의 다른 글
| 연결 리스트(Linked list) 1-2 (0) | 2020.01.15 |
|---|---|
| 연결 리스트(Linked List) 1-1 (0) | 2020.01.15 |
| 하노이 타워 (0) | 2020.01.15 |
| 함수의 재귀적 호출의 이해 (0) | 2020.01.05 |
| 이진 탐색(Binary Search)알고리즘과 빅-오 (0) | 2020.01.01 |