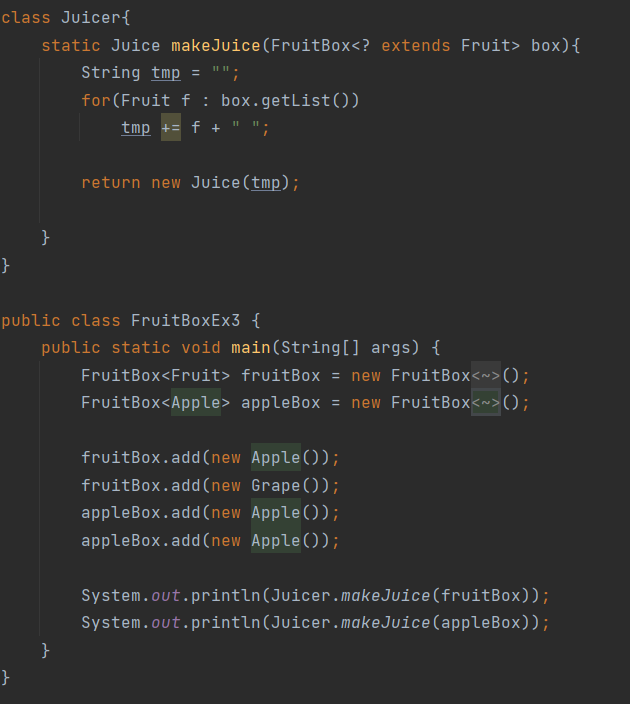
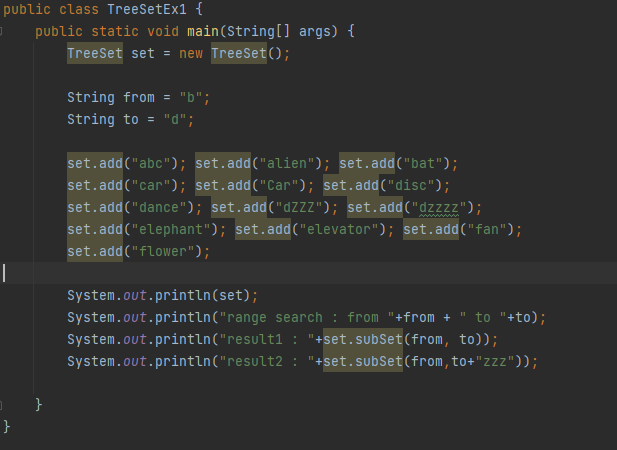
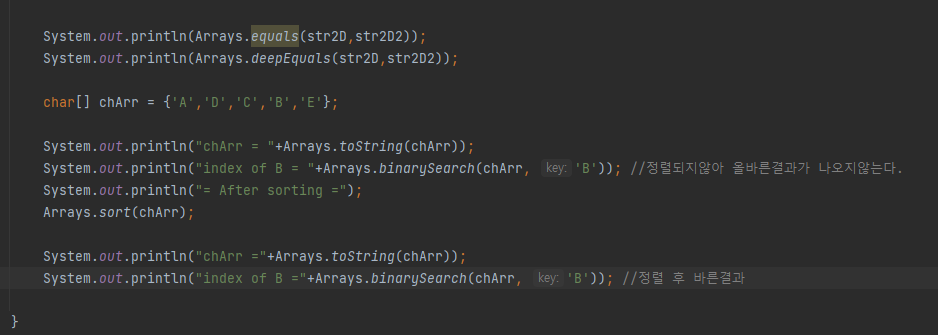
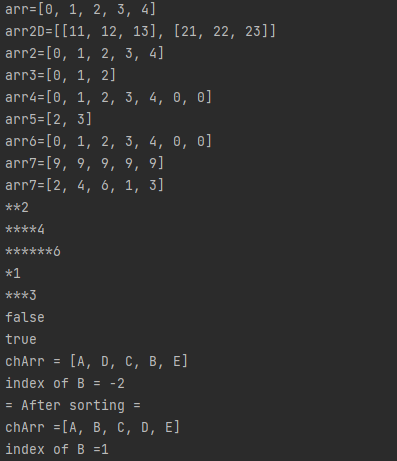
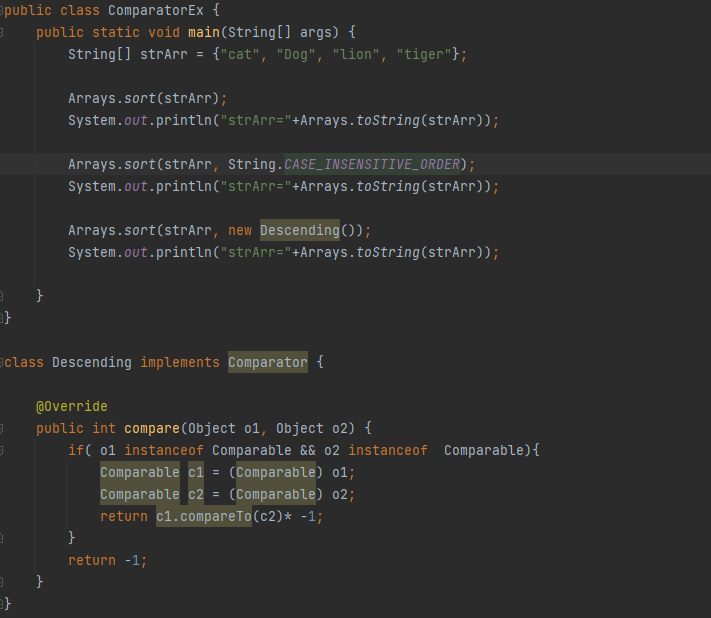
프로세스 쓰레드
프로세스 : 실행 중인 프로그램. 데이터와 메모리 등 프로그램을 수행하는데 필요한 자원과 쓰레드로 구성.
쓰레드 : 프로세스의 자원을 이용하여 실제로 작업을 수행하는 것
모든 프로세스는 하나 이사으이 쓰레드가 존재하며, 하나의 쓰레드를 가진 프로그램을 '싱글 쓰레드 프로세스', 두개이상의 쓰레드를 가진 프로세스를 '멀티쓰레드 프로세스'라고 한다.
쓰레드는 각각 쓰레드별로 작업공간을 가지며 프로세스의 자원에 따라 최대 생성할 수 있는 쓰레드가 결정된다. 그러나 일반적으로 프로세스 자원의 한계에 다다를 만큼 쓰레드를 생성하는 일은 거의 없다.
멀티태스킹과 멀티쓰레딩
멀티 태스킹(multi-tasking) : 여러개의 프로세스가 동시에 실행되는것.
멀티 쓰레드(multi-thread) : 하나의 프로세스 내에서 여러 쓰레드가 동시에 작업을 수행하는 것.
멀티쓰레딩의 장점
-자원을 효율적으로 사용할 수 있다.
-CPU의 사용률을 향상시킨다.
-사용자에 대한 응답성이 향상된다.
-작업이 분리되어 코드가 간결해진다.
서버 프로세스의 경우 여러개의 쓰레드로 클라이언트와의 연결시 각각 클라이언트와 쓰레드가 일대일로 처리되야한다.
싱글스레드로 서버프로그래밍을 할경우 클라이언트의 연결요청시마다 프로세스를 생성해야하는데 이때 자원이 많이 사용되기 때문에 많은 클라이언트에게 원활한 서비스를 제공하는것이 어려울 수 있다.
멀티쓰레드의 경우 프로세스의 자원을 공유하면서 작업을 하기 때문에 다양한 문제들을 고려하여 프로그래밍해야한다.
쓰레드의 구현과 실행
쓰레드를 구현하는 방법은 두가지가 있다.
1.Thread클래스를 상속받는 방법
2.Runnable인터페이스를 구현하는 방법
일반적으로 다중상속을 사용하기 위해 Runnable인터페이스를 구현하는 방법을 많이 사용한다.
Runnable인터페이스는 쓰레드의 작업을 작성하는 run()만 정의되어있다.
쓰레드를 구현하는 두가지 방법
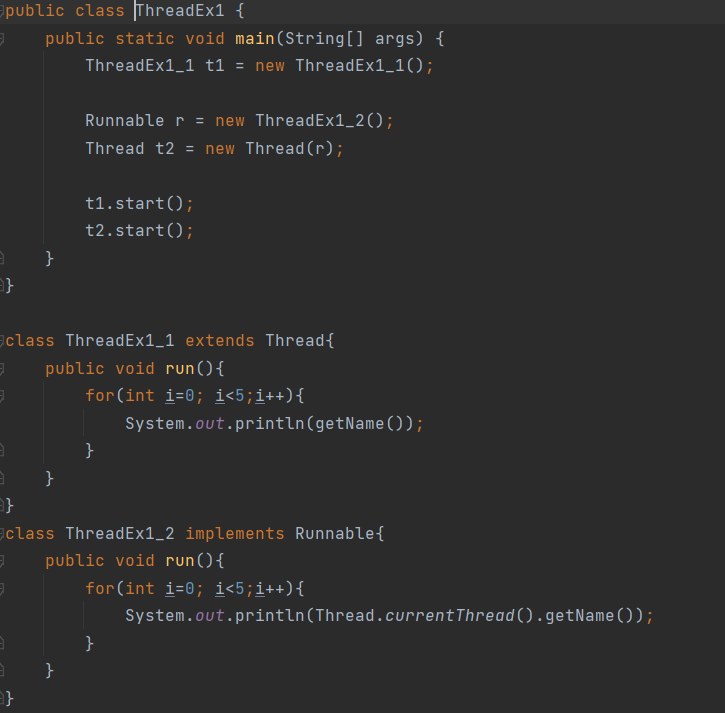
ThreadEx1_1의 경우 Thread클래스를 상속받아 쓰레드를 구현한 방식이고 ThreadEx1_2의 경우 Runnable인터페이스를 상속받아 인스턴스를 구현한 후 Thread클래스의 생성자의 매개변수로 Thread를 구현한 방식이다.
Runnable인터페이스를 상속받아 구현하는 경우 해당 클래스의 인스턴스를 생성하여 Thread클래스의 생성자 매개변수로 넣어 Thread를 생성해주어야한다.
main메서드에서 처럼 생성된 인스턴스 객체의 start()메서드를 호출하면 해당 쓰레드 클래스의 run()메서드에 정의된 작업이 실행된다.
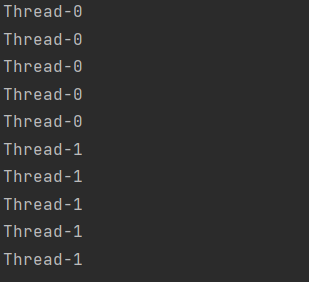
위예제의 실행결과이다. Thread이름을 가져와서 출력하는것인데 Thread클래스를 상속받은경우 getName()을 호출할경우 쓰레드의 이름을 얻을 수 있다. Runnable을 구현한 경우 run()밖에 없기 때문에 Thread.currentThread().getName()과 같이 Thread클래스의 currentThread()메서드를 호출한 후 getName()을 호출 해야한다.
쓰레드의 이름은 생성자나 메서드를 통해 지정 및 변경이 가능하다.
ex)
Thread(Runnable target, String name)
Thread(String name)
void setName(String name)
쓰레드의 실행 - start()
쓰레드를 실행시키는 것은 start()이다.
start()가 호출되면 쓰레드를 생성하여 실행대기 상태로 만든다. 이후 OS의 스케줄러에 의해 실행이 결정된다.
*Java 프로그램의 경우 JVM위에서 실행되기 때문에 보통 OS에 종속적이지 않지만 쓰레드는 JVM 과 관계없이 OS에 종속적이며 쓰레드의 실행순서는 OS스케줄러에 의해 결정된다.
java의 경우 실행후 종료된 쓰레드는 다시 실행시킬 수 없다. 즉 하나의 쓰레드에 대해 start()는 한번만 호출이 된다.
쓰레드의 작업 종료후 추가적으로 같은 작업을 위해 쓰레드를 생성해야 한다면 new 를 통해 새로운 쓰레드를 생성하여 같은작업을 실행시켜야 한다.
start()와 run()
쓰레드의 작업을 정의하는것은 run()이다. 그러나 쓰레드를 생성하고 실행시킬떄는 start()를 호출한다.
run()을 호출할 경우 Thread를 생성하는것이 아닌 단순히 해당 메서드를 호출하는 것 뿐이다.
start()는 새로운 쓰레드가 작업을 실행하는데 필요한 호출스택(call stack : 메모리상 작업공간)을 생성한 후 해당 호출스택에 run()을 호출하여 run()이 실행되도록 한다.
모든 쓰레드는 독립적인 작업을 수행하기 위해 자신만의 호출스택을 필요로 하기 때문에 새로운 쓰레드를 생성하고 실행시킬 때마다 새로 호출스택을 생성하고 쓰레드가 종료되면 호출스택을 반환(소멸)한다.
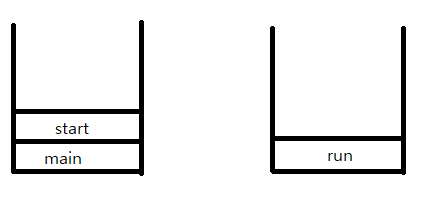
호출스택을 그림으로 나타낸 것이다. 호출스택에서 가장 위에있는 메서드가 현재 실행중인 메서드이다. 그리고 맨위(실행중)가 아닌 아래에있는 메서드들은 현재 대기상태에 있는 것이다.
멀티쓰레드 환경 즉 호출스택이 두개 이상인 경우 최상위 메서드라고 하더라도 대기상태일 수 있다.
실행중과 대기상태는 스케줄러가 결정하며 쓰레드들 우선순위에 따라 실행순서와 실행 시간을 스케줄러가 결정한다.
주어진시간동안 완료하지 못한 작업의 경우 해당 쓰레드는 대기상태로 전환되며 다시 자신의 실행차례가 오는것을 기다린다. run()에 정의된 작업을 완료한 쓰레드의경우 호출스택이 비워지며 호출스택을 반환한다.
main쓰레드
main메서드의 작업을 시작으로 다른 쓰레드들을 생성하거나 작업을 수행하는데 이떄 main메서드의 작업을 수행하는것을 main쓰레드라고 한다.
이때까지 해온 싱글 스레드 프로그래밍에서는 main메서드가 수행을 마치면 프로그램이 종료되었으나, 멀티 쓰레드 프로그래밍에서는 main메서드가 수행을 마치더라도 다른 쓰레드가 작업을 끝마치지 않았다면 프로그램은 종료되지 않는다.
프로세스는 실행중은 사용자 쓰레드가 하나도 없을 때 프로세스가 종료된다.
쓰레드는 '사용자 쓰레드(user thread)'와 '데몬 쓰레드(daemon thread)' 두개의 종류가 있다.
데몬 쓰레드의 경우 실행일지라도 사용자 쓰레드가 모두 작업을 종료하면 프로세스는 종료한다.
싱글쓰레드와 멀티쓰레드
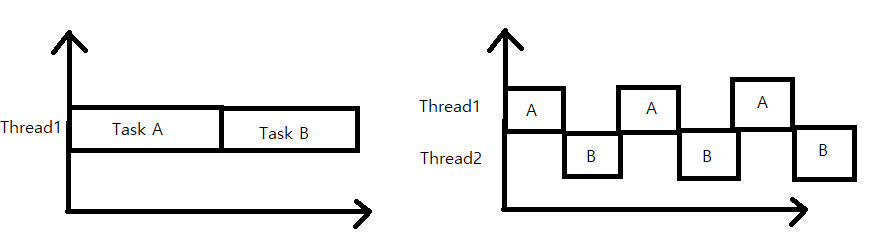
왼쪽의 그림의경우 싱글스레드로 두개의 작업을 한경우이고 오른쪽의 경우 두개의 쓰레드로 두개의 작업을 한경우이다.
보통 두개의 쓰레드로 작업한시간이 한개의 쓰레드로 작업을 한경우보다 시간이 더걸린다. 그 이유는 각 쓰레드간 작업 전환(context switching)에 시간이 걸리기 떄문이다.
단순한 계산이나 하나의 자원을 사용하는경우 싱글 스레드가 더효율적이다.
여러개의 쓰레드가 서로 다른 자원을 사용하는경우 싱글쓰레드보다 멀티쓰레드가 더 효율적이다.
일반적으로 I/O 작업을 하는경우인데 네트워크로 데이터를 송수신하는경우, 사용자로부터 데이터를 입력받고 사용자에게 데이터를 출력하는경우, 프린터 출력과 같이 외부기기와의 입출력을 하는경우 등 I/O작업이 동반되는 경우 멀티쓰레드가 더 효율적이다.
하나의 쓰레드가 I/O를 진행하는동안 다른쓰레드는 작업이 가능하기 때문이다.
'Programming > JAVA' 카테고리의 다른 글
| 데몬 쓰레드(daemon thread) (0) | 2021.08.13 |
|---|---|
| 쓰레드 우선순위와 쓰레드 그룹 (0) | 2021.08.13 |
| 에너테이션(annotation) (0) | 2021.08.11 |
| 열거형(Enums) (0) | 2021.08.10 |
| 지네릭스(Generics) (0) | 2021.08.07 |