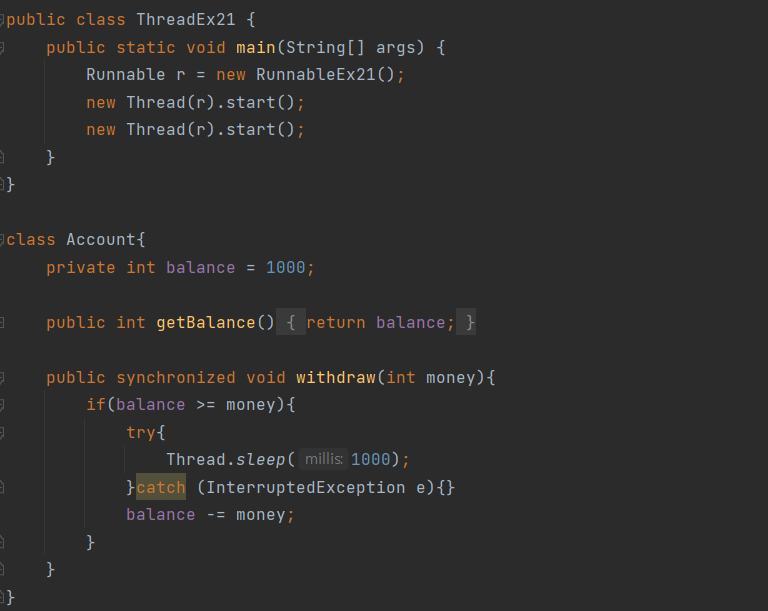
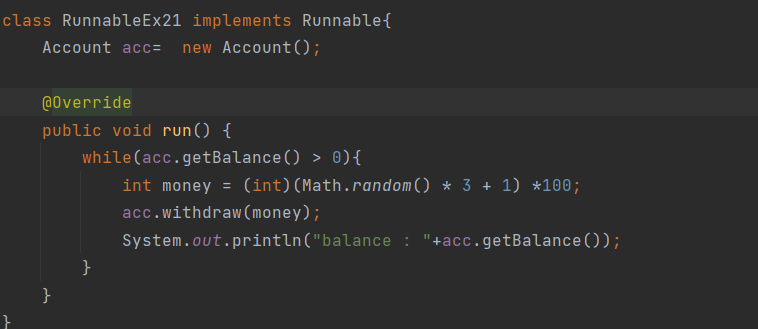
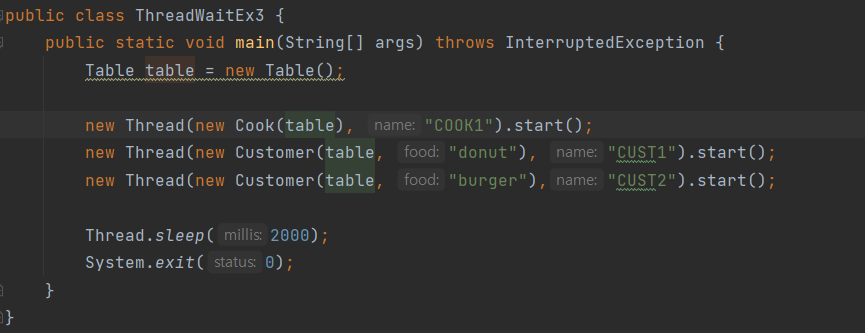
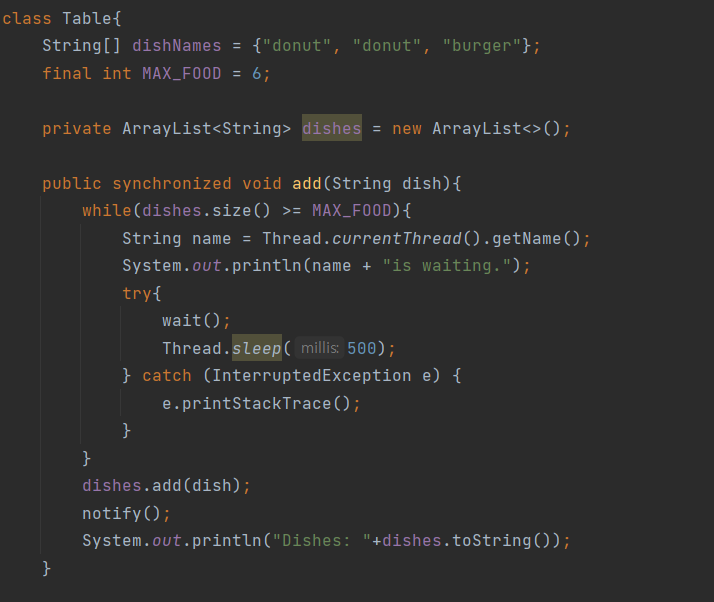
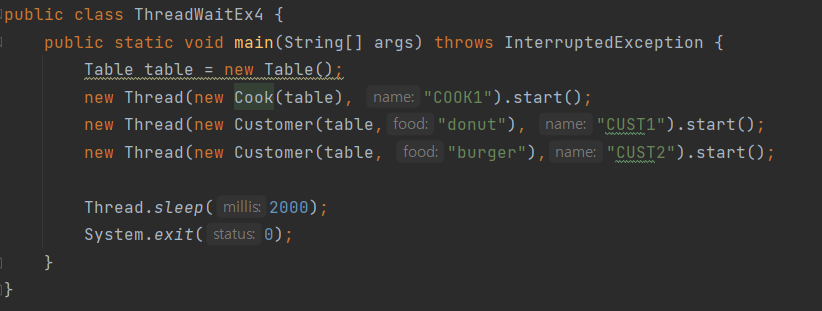
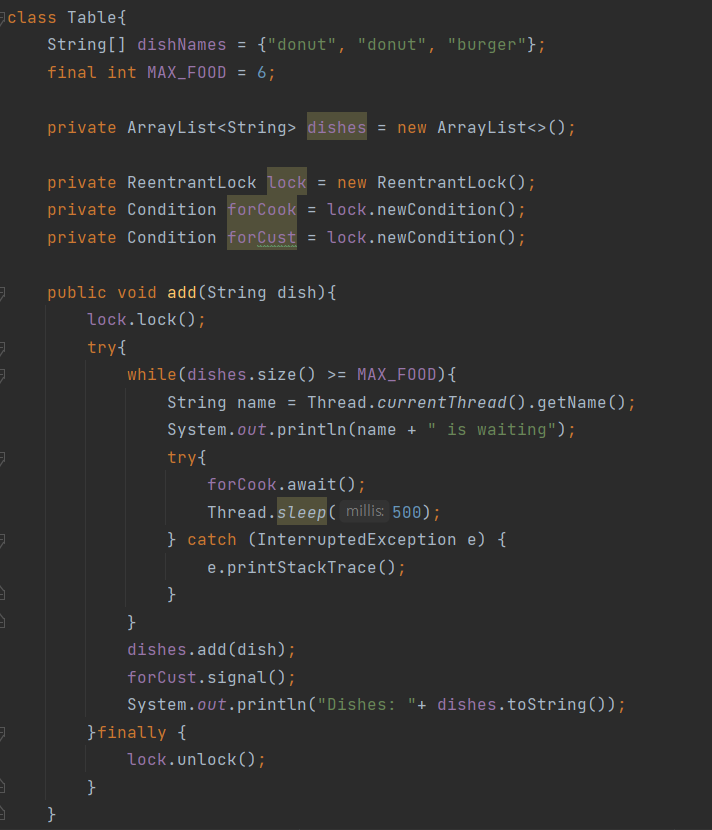
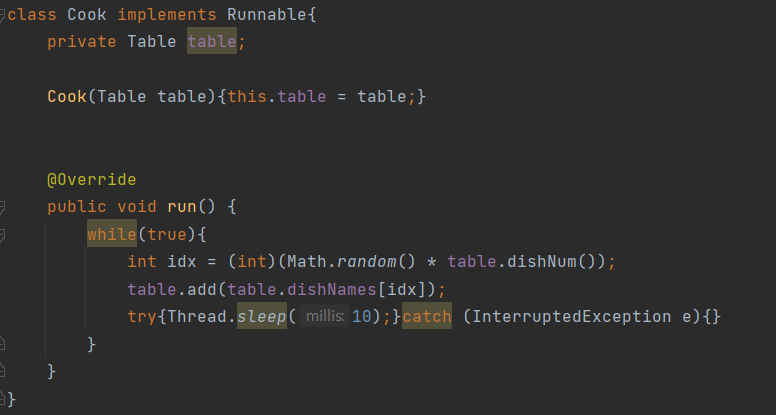
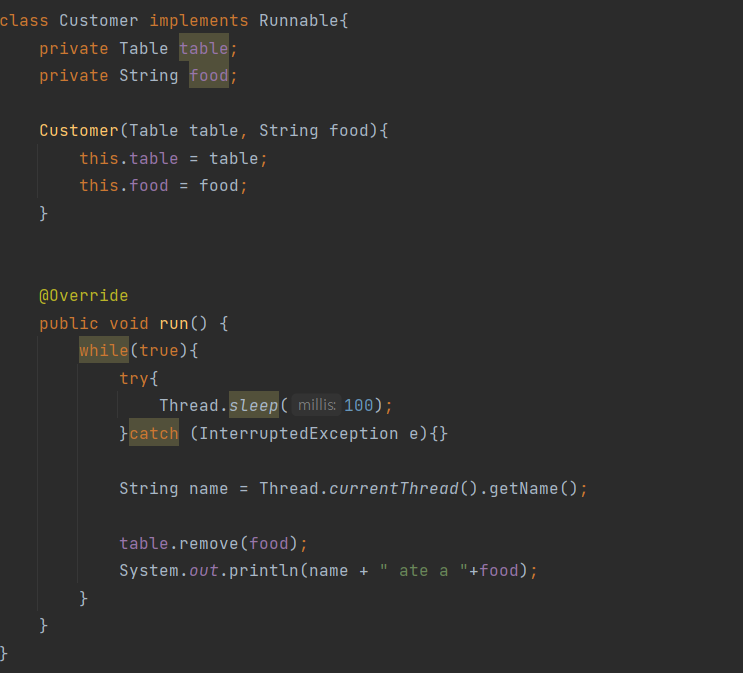
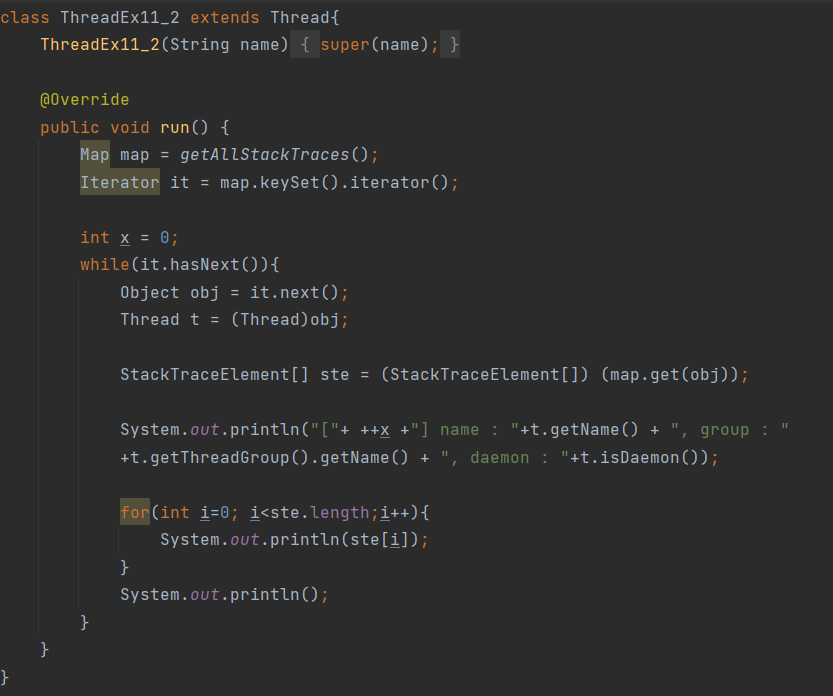
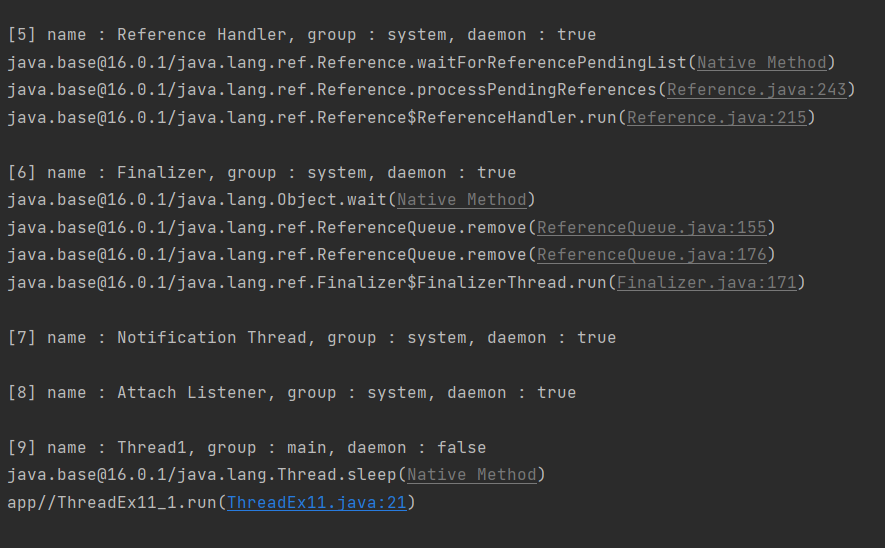
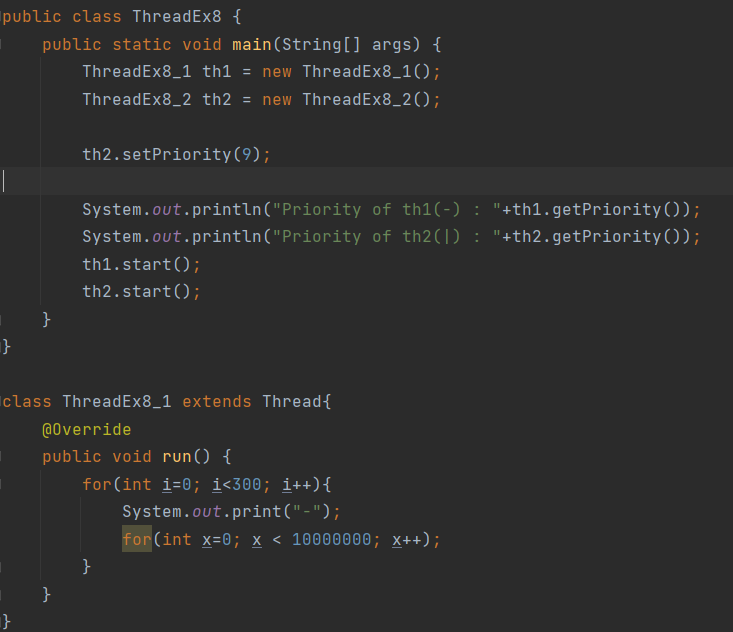
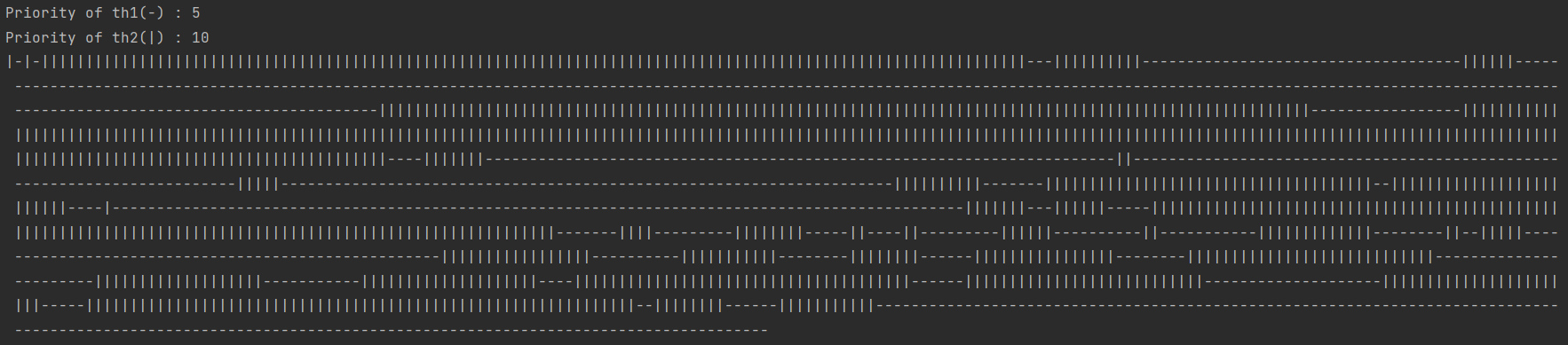
스트림
스트림 : 다양한 데이터소스를 표준화된 방법으로 다루기 위한 것.
스트림은 데이터를 추상화하고, 데이터를 다루는데 자주 사용되는 메서드들을 정의해 놓았다.
스트림은 스트림 생성 -> 중간연산(0~n번) ->최종연산(1번) 으로 사용된다.
스트림의 특징
1.스트림은 데이터 소스를 변경하지 않는다.
스트림은 데이터를 읽기만 할 뿐, 데이터 소스를 변경하지 않는다. 데이터를 정렬하거나 중복제거 등은 가능하지만 데이터 값을 변경하는것은 불가능하다.(Read only)
2.스트림은 1회용이다.
스트림의 경우 최종연산을 하게되면 해당 스트림이 닫힌다. 닫힌 스트림은 사용할 수 없으며 사용시 에러가 발생한다.
3. 스트림의 작업은 내부 반복으로 처리한다.
내부 반복 : 반복문을 메서드의 내부에 숨길 수 있다.
forEach()의 경우 스트림에 정의된 메서드로 매개변수에 대입된 람다식을 데이터 소스의 모든 요소에 적용시켜주는 메서드이다.
4.스트림의 연산
1.중간연산 : 연산 결과가 스트림을 반환하는 연산. 스트림에 연속적으로 연산가능
2.최종연산 : 연산 결과가 스트림이 아닌 연산. 스트림의 요소를 소모하기 때문에 스트림당 한번만 수행이 가능
최종연산 이후에는 스트림이 닫히기 때문에 최종연산은 한번만 가능하다.
연산목록
중간연산
Stream<T> distinct() : 중복 제거
Stream<T> filter(Predicate<T> predicate) : 조건에 안맞는 요소 제외
Stream<T> limit(long maxSize) : 스트림의 개수 지정
Stream<T> skip(long n) : 스트림의 일부를 건너 뛴다.
Stream<T> peek(Consumer<T> action) : 스트림의 요소에 작업 수행
Stream<T> sorted()
Stream<T> sorted(Comparator<T> comparator)
:스트림의 요소 정렬
Stream<R> map(Function<T,R> mapper) : 스트림의 요소 변환
최종연산
void forEach(Consumer<? super T> action) : 각 요소에 지정된 작업 수행
long count() : 스트림 요소 개수 반환
Optional<T> max(Comparator<? super T> comparator) : 스트림의 최대값 반환
Optional<T> min(Comparator<? super T> comparator) : 스트림의 최소값을 반환
Optional<T> findAny(), Optional<T> findFirst() : 스트림의 요소 하나를 반환
boolean allMatch(Predicate<T> p) : 모든 요소가 조건을 만족하는지 확인
boolean anyMatch(Predicate<T> p) : 하나의 요소라도 해당 조건을 만족하는지 확인
boolean noneMatch(Predicate<> p) : 모든 요소가 조건을 만족하지 않으면 true
Object[] toArray(), A[] toArray(IntFunction<A[ ]> generator) : 스트림의 모든 요소를 배열로 변환
Optional<T> reduce(BinaryOperator<T> accumulator)
T reduce(T identity, BinaryOperator<T> accumulator)
U reduce(U identity, BiFunction<U, T, U> accumulator, BinaryOperator<U> combiner)
: 스트림의 요소를 하나씩 줄여 가면서 계산한다.
R collect(Collector<T,A,R> collector)
R collect(Supplier<R> supplier, BiConsumer<R, T> accumulator, BiConsumer<R, R> combiner)
: 스트림의 요소를 수집한다. 주로 요소를 그룹화 하거나 분할한 결과를 컬렉션에 담아 반환하는데 사용된다.
스트림 연산에서 중요한점은 최종연산이 수행되기 전까지 중간 연산은 수행되지않는다.
중간연산을 호출하더라도 즉각적인 연산이 수행되는것이 아니다.
최종 연산이 수행되어야 스트림의 요소들이 중간연산을 거쳐 최종 연산에서 소모된다.
5.기본형 스트림
스트림은 기본적으로 Stream<T> 형태이지만, 오토박싱&언박싱으로 인한 비효율을 줄이기 위해 데이터 소스의 요소를 기본형으로 다루는 스트림, IntStream, LongStream, DoubleStream이 제공된다.
일반적으로 Stream<Integer> 보다 IntStream을 사용하는것이 더 성능이 좋다. 또한 IntStream과 같이 기본형이 적용된 스트림의 경우 기본형에 대한 작업에 유용한 메서드들이 더 존재한다.
6.병렬 스트림
스트림으로 데이터를 처리할 때 장점이 병렬처리가 쉽다는 것이다.
병렬스트림으로 전환하는 경우 parallel()이라는 메서드를 사용하는데 해당 메서드를 호출하면 스트림이 병렬 스트림으로 전환된다. 병렬로 처리되지 않게 하려면 sequential()을 호출하면 된다.
스트림 만들기
스트림의 소스가 될 수 있는 대상은 배열, 컬렉션, 임의의 수 등이 있다. 이러한 소스들을 이용하여 스트림을 만들 수 있다.
컬렉션
Collection에 stream()메서드라 정의되어 있어 해당 메소드를 호출하면 스트림을 생성할 수 있다.
stream()메서드는 해당 컬렉션을 소스로 하는 스트림을 반환한다.
Stream<T> Collection.stream()
ex)
List<Integer> list = Arrays.asList(1,2,3,4,5);
Stream<Integer> intStream = list.stream();
배열
배열을 소스로하는 스트림을 생성할 때는 Stream과 Arrays에 정의되어있는 static메서드로 생성할 수 있다.
Stream<T> Stream.of(T ... values)
Stream<T> Stream.of(T[])
Stream<T> Arrays.stream(T[])
Stream<T> Arrays.stream(T[ ] array, int startInclusive, int endExclusive)
특정 범위의 정수
IntStream과 LongStream은 지정한 범위의 연속된 정수를 스트림으로 생성해서 반환할 수 있다.
IntStream IntStream.range(int begin, int end)
IntStream IntStream.rangeClosed(int begin, int end)
range()는 begin ~ end-1까지의 수를 스트림으로 생성하고 rangeClosed()는 begin ~ end 까지의 수를 스트림으로 생성한다.
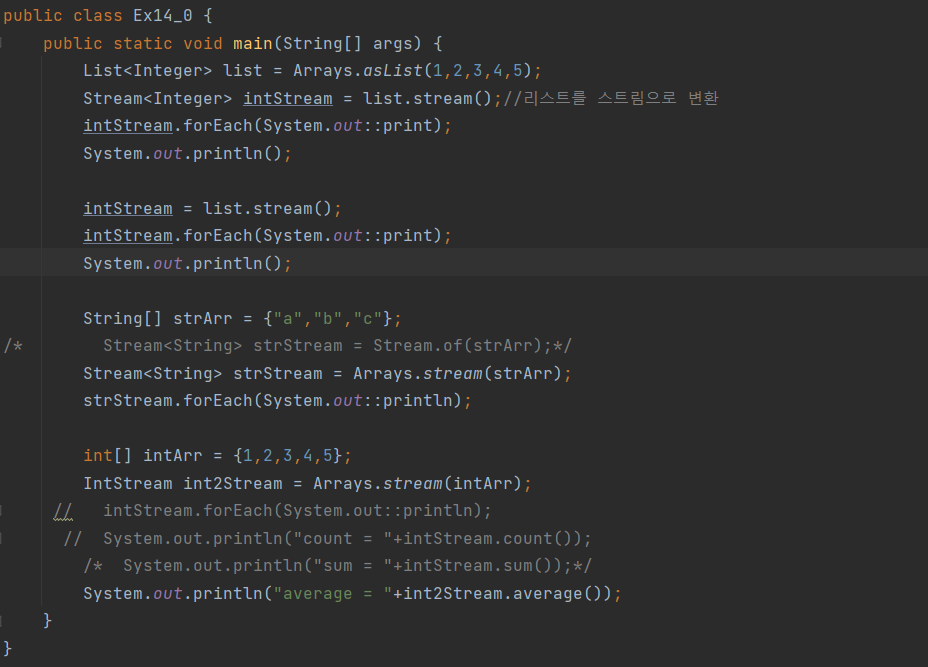

forEach()는 매개변수로 들어온 람다식의 작업을 스트림의 모든요소에 대해 수행한다.
intStream.forEach(System.out::println);
foroEach()가 스트림의 요소를 소모하면서 작업을 수행하므로 같은 스트림에 forEach()를 두 번 호출할 수 없다.
스트림의 요소를 한번 더 출력하려면 스트림을 새로 생성해야 한다.
임의의 수
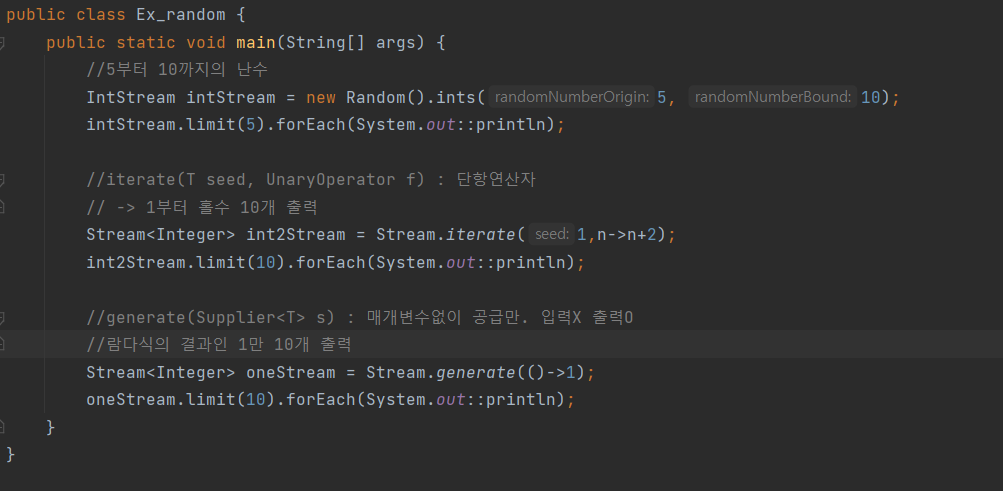
난수를 생성하는데 사용하는 Random클래스에 난수들로 이루어진 스트림을 반환하는 메서드가 있다.
IntStream ints()
LongStream longs()
DoubleStream doubles()
위 메서드들이 반환하는 스트림은 크기가 정해지지 않은 '무한 스트림(infinite stream)' 이다.
스트림의 개수를 지정해주는 limit()을 함께 사용하여 무한스트림을 유한 스트림으로 만들어 주어야한다.
ex)
IntStream intStream = new Random().ints();
intStream.limit(5).forEach(System.out::println);
위처럼 무한스트림을 유한스트림으로 변경하여 5개의 정수형 난수를 출력 할수 있다.
IntStream ints(long streamSize)
LongStream longs(long streamSize)
DoubleStream doubles(long streamSize)
위 메서드들은 지정된 크기에 해당하는 '유한 스트림'을 생성하여 반환한다.
람다식 - iterate(), generate()
iterate()와 generate()는 람다식을 매개변수로 받아 람다식에 해당하는 결과를 요소로하는 무한 스트림을 생성하여 반환한다.
static <T> Stream<T> iterate(T seed, UnaryOperator<T> f)
: seed값부터 시작해서 람다식 f에 의해 계산된결과를 스트림에 요소에 포함시키며 해당 결과를 다시 seed값으로 넣어 계산을 반복한다.
static <T> Stream<T> generate(Supplier<T> s)
: seed값 없이 s의 결과로만 무한 스트림을 생성한다.
'Programming > JAVA' 카테고리의 다른 글
| Optional (0) | 2021.08.25 |
|---|---|
| 스트림(Stream)의 중간연산 (0) | 2021.08.25 |
| 다양한 함수형 인터페이스 & 메서드 참조 (0) | 2021.08.22 |
| 람다식(Lambda expression) (0) | 2021.08.21 |
| fork & join (0) | 2021.08.20 |