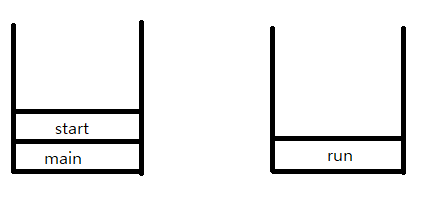공유데이터에 여러 쓰레드가 동시에 접근하게 되면 프로그래머의 의도와 다르게 동작할 수 있기 때문에 동기화를 통해 공유 데이터에 대한 동시접근 문제를 해결 할 수 있다.
공유데이터를 사용하는 코드 영역을 임계 영역 이라한다. 공유데이터(객체)가 가지고 있는 lock을 획득한 쓰레드만 영역내의 코드를 수행하고 해당 영역 코드실행을 완료했을경우 lock을 반납할 수 있다. lock은 하나만 존재하며 임계영역에는 하나의 쓰레드만 접근이 가능하다.
synchronized를 사용한 동기화
synchronized 키워드를 사용하여 동기화가 가능하다.
1.메서드를 임계영역으로 지정
ex)
public synchronized void calcSum(){
...
}
메서드에 synchronized 키워드를 붙일 경우 메서드 전체가 임계영역으로 설정되고, 쓰레드는 synchronized메서드가 호출된 시점부터 메서드의 객체 lock을 얻어 작업을 수행한다. 이후 해당 메서드의 작업이끝나면 메서드의 객체 lock을 반환한다.
2.특정한 영역을 임계영역으로 지정
ex)
synchronized(객체의 참조변수){
...
}
메서드 내의 임의의 코드를 블럭{ }으로 감싸고 블럭 앞에 synchronized(참조변수)를 붙이는 것이다. 매개변수형태로 되어있는 참조변수에는 락을 걸고자 하는 객체를 참조하는 것이여야한다. 일반적으로 this를 사용한다.
이러한 블럭을 synchronized블럭이라 하며 이 블럭 영역 내의 코드를 실행하면서 지정한 객체의 lock을 얻고 블럭내의 코드를 모두 실행한 후 블럭을 빠져나갈때 lock을 반환한다.
synchronized키워드를 이용한 쓰레드 동기화의 경우 영역만 지정해주면 자동으로 lock을 얻고 반환한다.
모든 객체는 lock을 하나씩 가지고 있으며, 해당 객체의 lock을 가진 쓰레드만 객체내의 임계영역 코드를 실행할 수 있다. 그리고 다른 쓰레드들은 lock을 얻기위해 기다리게된다. 임계영역은 멀티쓰레드 프로그램에서 프로그램의 성능을 좌우할 수 있기 때문에 임계영역을 최소화하거나 동기화를 잘 조절하여 효율적인 프로그램이 되도록 해야한다.
임계영역에서 사용되는 공유데이터는 private여야 한다. synchronized는 지정된 코드를 한번에 하나의 쓰레드만 접근 가능하도록 했을 뿐이기 때문에 다른방면에서의 데이터접근을 막기 위해서는 private로 설정해야한다.
wait()과 notify()
특정쓰레드가 객체 lock을 가진상태에서 오랜시간이 지나지않도록, 임계영역코드를 수행하다가 작업을 더이상 수행하지 못하는 상황을 해결하기위해 wait()과 notify()가 고안되었다.
lock을 가지고있는 쓰레드가 wait()을 호출하면, 작업중이던 쓰레드는 lock을 반납하고 해당 객체의 대기실(waiting pool : 객체의 lock을 얻기위해 대기하는 쓰레드 대기실)로 이동하여 notify()를 기다린다. notify()가 호출되면, 해당 객체 대기실에 있던 쓰레드중 임의의 쓰레드만 통지(lock)을 받아 임계영역에 접근한다.
notifyAll()은 객체의 대기실에 존재하는 모든 쓰레드들에게 통보를 하지만 lock을 얻을 수 있는 쓰레드는 한개 뿐이다.
main메소드
위처럼 코드를 짜면 각 메소드에 동시접근 문제를 해결할 수 있다.
그러나 객체의 lock은 하나이기 때문에 COOK쓰레드가 add를 하거나 CUST1, CUST2가 remove를 할때 각각 쓰레드들은 대기를 해야한다. 즉 COOK이 호출하는 table.add()와 CUST의 table.remove()는 동시에 작동할 수 없다.
또한 각 작업을 마치고 notify()가 호출되어도 CUST와 COOK중 어느쓰레드가 lock얻게되어 작업을 수행하게 될지 알 수 없다. CUST쓰레드가 많고 COOK쓰레드는 하나라면 최악의 경우 COOK은 lock을 오랜시간 얻지못하여 프로그램이 '기아(starvation) 현상'에 빠질 수 있다.
이러한 경우를 막기위해 notifyAll()을 사용하여 모든 쓰레드에게 공정하게 lock을 얻을 기회를 줄 수 있는데 이또한 문제가 발생할 수 있다. 하나의 COOK쓰레드가 많은수의 CUST쓰레드와 lock을 얻기위한 '경쟁 상태(race condition)'에 빠질 수 있기 때문이다.
두개의 쓰레드는 같은 객체의 다른메소드를 호출하기 때문에 경쟁상대가 되어서는 안된다. 하지만 객체의 lock은 하나이기 때문에 wait()과 notify()를 이용한 lock제어에서는 경쟁상대가 될 수 밖에없다.
Lock과 Condition을 이용하면 wait()과 notify()에서는 불가능한 선별적인 통지가 가능하다.
Lock & Condition
synchronized키워드가 아닌 'java.util.concurrent.locks' 패키지에서 제공하는 lock클래스를 이용하여 동기화를 하는 방법이 있다. lock클래스를 통해 동기화를 할경우 같은객체내에서 메소드별로 lock을 생성할 수 있다.
lock클래스의 종류
ReentrantLock : 재진입이 가능한 lcok, 가장 일반적인 lock. lock이 있어야만 임계영역 코드를 수행할 수 있다.
StampedLock : lock을 걸거나 해지할 때 '스탬프(long 타입의 정수값)'를 사용한다.
ReentrantLock의 생성자
ReentrantLock()
ReentrantLock(boolean fair)
생성자 매개변수를 true로 주면, lock이 풀렸을 때 가장 오래 기다린 쓰레드가 lock을 얻을 수 있도록, 공정(fair)하게 처리한다. 공정하게 처리하기 위해 쓰레드들을 확인하는 과정이 생겨나므로 성능은 좀 떨어진다.
void lock() : lock을 잠근다.
void unlock() : lock을 해지한다.
boolean isLocked() : lock이 잠겼는지 확인한다.
synchronized동기화와 달리, ReentrantLock과 같은 lock클래스들은 수동으로 lock을 잠구고 해제해야한다.
임계영역 내에서 예외가 발생하거나 return으로 빠져나가게 되면 unlock()을 수행하지 못하는 경우가 생길 수 있으므로 unlock()은 try-finally문으로 감싸는것이 일반적이다.
ex)
lock.lock();
try{
...
} finally{
lock.unlock();
}
try블럭내에서 어떤 코드를 실행하더라도 마지막엔 반드시 finally블록 코드를 실행하기 때문에 finally블럭에 lock.unlock()을 넣어주는 것이다.
선별적인 통지를 위해서는 Condition이 필요하다. 위예제의 문제점을 해결하기 위해서는 손님쓰레드를 위한 Condition과 요리사 쓰레드를 위한 Condition을 만들어서 각각의 waiting pool에서 따로 기다리게 하는것이다.
Condition은 이미 생성된 lock으로 부터 newCondition()을 호출하여 생성한다.
private ReentrantLock lock = new ReentrantLock();
private Condition forCook = lock.newCondition();
private Condition forCust = lock.newCondition();
위코드에서 두개의 Condition을 생성하였다.
이후 wait(), notify()대신 await() & signal()을 사용하면된다.
Table클래스의 코드를 보면 ReentrantLock클래스를 통해 lock생성과 두개의 Condition생성을 볼 수 있다.
또한 add메서드에서 음식이 꽉찼다면 forCook.await()을 통해 Cook 쓰레드를 대기시키고 forCust.signal()을 통해 CUST쓰레드를 작업을 하도록 만든다. remove()메서드 또한 음식의 개수가 0개일때 CUST쓰쓰레드를 forCust.await()을 통해 대기시키고 forCook.signal()을 통해 COOK쓰레드를 실행시킨다.
위처럼 reentrantLock클래스와 Condition을 사용할경우 필요한 상황에 맞춰 작업을 수행하는 쓰레드들에 대해 선별적인 동기화를 적용해줄 수 있다. 기아현상이나 경쟁현상이 많이 줄어든 예제이다.
효율적인 멀티쓰레드 프로그램은 스케줄링을 적절하게 조절하여 자원과 시간의 낭비 없이 잘 동작하게 하는 프로그램이다.
쓰레드의 스케줄링을 위한 쓰레드 상태와 관련 메서드이다.
쓰레드 상태
NEW : 쓰레드가 생성되고 start()가 호출되지 않은 상태
RUNNABLE : start()가 호출되고 쓰레드가 실행중 또는 실행 대기인 상태
BLOCKED : 동기화 블럭에 의해 쓰레드가 일시정지된 상태
WAITING, TIMED_WAITING : 쓰레드의 작업이 종료되지는 않았으나 실행대기 또는 실행중(RUNNALBE)이 아닌 일시정지 상태.
TERMINATED : 쓰레드의 작업이 종료된 상태
쓰레드 메서드
static void sleep(long millis), static void sleep(long millis, int nanos) : 지정된 시간(천분의 일초 단위)동안 쓰레드를 일시정지시킨다. 지정한 시간이 지나고 나면 실행대기상태가 된다.
void join(), void join(long millis), void join(long millis, int nanos) : 지정된 시간동안 쓰레드가 일시정지상태가 되도록한다. 지정한 쓰레드가 종료되면 join()을 호출한 쓰레드로 돌아와 실행을 계속한다.
void interrupt() : sleep()이나 join()에 의해 일시정지 상태인 쓰레드를 깨워서 실행대기 상태로 만든다. 해당 쓰레드에서는 InterruptedException이 발생 함으로써 일시정지 상태를 벗어나게 한다.
void stop() : 쓰레드를 즉시 종료시킨다.
void suspend() : 쓰레드를 일시정지 시킨다. resume()을 호출하면 다시 실행대기상태가 된다.
void resume() : suspend()에 의해 일시정지상태에 있는 쓰레드를 실행대기상태로 만든다.
static void yield() : 실행중에 자신의 실행시간을 다른쓰레드에게 양보(yield)하고 자신은 실행대기 상태가 된다.
suspend(), resum(), stop() 모두 교착상태(deadlock)을 유발할 위험이 있어 Deprecated(사용을 권장하지 않음)로 처리되어있다.
쓰레드를 생성하고 start()를 호출하면 바로 실행되는것이아니라 실행대기 상태가 되어 실행대기열에 저장된다.
실행대기열은 큐(queue)구조로 되어있으며 먼저 실행대기열에 들어온 순서대로 실행된다.
실행대기열에 있는것이 실행대기상태이다. 실행대기상태에서 자신의 차례가 되면 실행상태가된다.
OS 스케줄러에서 부여한 실행시간이 다되거나 yield()를 호출하면 실행대기상태가 되어 실행대기열에 다시 들어간다. 이후 실행대기열에 있던 다음쓰레드가 실행된다.
실행중에 suspend(), sleep(), wait(), join(), I/O block에 의해 쓰레드가 일시정지 상태가 될 수 있다. I/O block의 경우 사용자의 입력을 기다리는 경우가 있는데 사용자 입력을 마치면 다시 실행대기상태가 된다.
wait, sleep, suspend, join 일경우 일시정지시간이 끝나거나, notify(), resum(), interrupt()가 호출되어 일시정지상태를 벗어나 실행대기상태가 될 수 있다. 실행대기열에 들어가 실행을 기다린다.
쓰레드의 작업을 모두 끝내거나 stop()호출에 의해 쓰레드가 소멸된다.
sleep(long millis) - 일정시간동안 쓰레드를 멈추게 한다.
sleep()은 try-catch문을 필요로한다.
ex)
try{
Thread.sleep(1, 500000);
}catch(InterruptedException e) {}
}
sleep()으로 쓰레드를 0.0015초 멈춘 예제이다. sleep은 본인 쓰레드만 정지가 가능하며 sleep()에 의해 일시정지된 쓰레드는 지정된 시간이 다되거나 interrupt()가 호출되면 InterruptedException이 발생하며 깨어나 실행대기상태가 된다.
sleep()을 호출할경우 항상 try-catch문으로 예외처리를 해주어야한다.
interrupt(), interrupted() - 쓰레드의 작업을 취소한다.
진행중인 쓰레드의 작업이 완료되기전에 해당 쓰레드를 취소하는 경우가 발생할 수 있다.
interrupt()는 쓰레드에게 작업을 멈추라고 요청한다. 해당 메서드를 통해 쓰레드를 멈출 수 는 있지만 멈추라고 요청만 할 뿐 쓰레드를 강제 종료시키지는 못한다. interrupt()는 interrupted상태로 변경하는 메서드이다.
boolean isInterrupted() : 쓰레드의 현재 interrupt상태를 반환한다.
static boolean interrupted() : 현재 쓰레드의 interrupted상태를 반환하고 false로 변경한다.
쓰레드가 sleep(), wait(), join()등에 의해 일시정지 상태(WAITING)일 경우 interrupt()를 호출하면 InterruptedException이 발생하고 쓰레드는 실행대기 상태(RUNNABLE)상태로 변경된다. 즉. 멈춰있던 쓰레드를 실행가능한 상태로 만드는 것이다.
ThreadEx13_1에 의해 10부터 0까지 1씩 감소하지만 main Thread에서 입력을 완료할경우 쓰레드에 interrupt()를 발생시킨다.
진행중인 쓰레드는 Interrupted()함수 호출을 통해 계속해서 interrupt상태값을 검사하다가 interrupt()호출에 의해 상태값이 변화하면 반복을 멈추고 카운트를 종료시킨다.
이처럼 Interrupt()와 Interrupted()를 통해 진행중인 쓰레드를 중지시킬 수 있다.
interrupted() 호출 시 interrupted상태값이 false로 변경되는것도 알 수 있다.
위예제의 경우 입력을 완료하더라도 계속해서 카운트를 진행시키는데 코드는 파란색 동그라미 부분이 추가되었다.
위 코드에서 Interrupt가 발생하여 반복을 멈추지 않은 이유는 InterruptException이 발생했기 때문이다.
sleep()상태에서 Interrupt()호출시 InnterruptedException 처리가 되면 쓰레드의 interrupted상태값은 false로 자동 초기화된다. 출력이 true로 된것은 쓰레드에서 InterruptedException처리가 되기 전에 출력해서 true가 출력되는것 같다.
정상적으로 모두 반복되는것을 보면 InterruptedException시 쓰레드의 interrupted상태는 false가 되는것을 알 수 있다.
interrupt발생시 프로그램을 멈추고 싶다면
try{
Thread.sleep(1000);
}catch(InterruptedException e){
interrupt();
}
로 수정하면 InterruptedException예외가 발생하더라도 interrupt상태값을 수정할 수 있다.
suspend(), resume(), stop()
void suspend() : 쓰레드를 sleep()처럼 일시정지 시킨다.
void resume() : suspend()에 의해 일시정지된 쓰레드를 실행대기상태로 만든다.
void stop() : 쓰레드를 즉시 종료시킨다.
위 메서드들은 교착상태(deadlock)를 일으키기 쉽게 작성되어있어 사용을 권장하지않는다.(Deprecated)
yield() - 다른 쓰레드에게 양보한다.
yield()는 쓰레드 자신에게 주어진 실행시간을 다음 차례의 쓰레드에게 양보(yield)한다.
출력으로는 확인할 수 없지만 실행시켜보면 yield()를 통해 프로그램의 응답성이 증가하였다.
효율적인 멀티쓰레드 프로그램을 위해서는 yield()를 적절히 사용해주어야 할것이다.
join() - 다른 쓰레드의 작업을 기다린다.
join() : 쓰레드 자신이 하던 작업을 잠시 멈추고 다른 쓰레드가 지정된 시간동안 작업을 수행하도록 할 때 join()을 사용한다.
void join()
void join(long millis)
void join(long millis, int nanos)
시간을 지정해주지 않을경우 쓰레드가 작업을 모두 마칠 때까지 기다리게된다.
ex)
try{
th1.join();
}catch(InterruptedException e){}
join()도 sleep()처럼 interrupt()에 의해 대기상태에서 벗어날 수 있으며, join()이 호출되는 부분또한 sleep()처럼 try-catch구문으로 감싸야 한다.
join()이 sleep()과 다른점은 static 메서드가 아니기때문에 현재 쓰레드가 아닌 특정 쓰레드에대해 동작한다는 것이다.
join()을 사용하지 않았다면 main 쓰레드가 소요시간을 출력하고 바로 종료됐겠지만 join()에 의해 쓰레드가 모두 끝난후 출력하고 main 쓰레드가 종료하게 된다.
프로세스 : 실행 중인 프로그램. 데이터와 메모리 등 프로그램을 수행하는데 필요한 자원과 쓰레드로 구성.
쓰레드 : 프로세스의 자원을 이용하여 실제로 작업을 수행하는 것
모든 프로세스는 하나 이사으이 쓰레드가 존재하며, 하나의 쓰레드를 가진 프로그램을 '싱글 쓰레드 프로세스', 두개이상의 쓰레드를 가진 프로세스를 '멀티쓰레드 프로세스'라고 한다.
쓰레드는 각각 쓰레드별로 작업공간을 가지며 프로세스의 자원에 따라 최대 생성할 수 있는 쓰레드가 결정된다. 그러나 일반적으로 프로세스 자원의 한계에 다다를 만큼 쓰레드를 생성하는 일은 거의 없다.
멀티태스킹과 멀티쓰레딩
멀티 태스킹(multi-tasking) : 여러개의 프로세스가 동시에 실행되는것.
멀티 쓰레드(multi-thread) : 하나의 프로세스 내에서 여러 쓰레드가 동시에 작업을 수행하는 것.
멀티쓰레딩의 장점
-자원을 효율적으로 사용할 수 있다.
-CPU의 사용률을 향상시킨다.
-사용자에 대한 응답성이 향상된다.
-작업이 분리되어 코드가 간결해진다.
서버 프로세스의 경우 여러개의 쓰레드로 클라이언트와의 연결시 각각 클라이언트와 쓰레드가 일대일로 처리되야한다.
싱글스레드로 서버프로그래밍을 할경우 클라이언트의 연결요청시마다 프로세스를 생성해야하는데 이때 자원이 많이 사용되기 때문에 많은 클라이언트에게 원활한 서비스를 제공하는것이 어려울 수 있다.
멀티쓰레드의 경우 프로세스의 자원을 공유하면서 작업을 하기 때문에 다양한 문제들을 고려하여 프로그래밍해야한다.
쓰레드의 구현과 실행
쓰레드를 구현하는 방법은 두가지가 있다.
1.Thread클래스를 상속받는 방법
2.Runnable인터페이스를 구현하는 방법
일반적으로 다중상속을 사용하기 위해 Runnable인터페이스를 구현하는 방법을 많이 사용한다.
Runnable인터페이스는 쓰레드의 작업을 작성하는 run()만 정의되어있다.
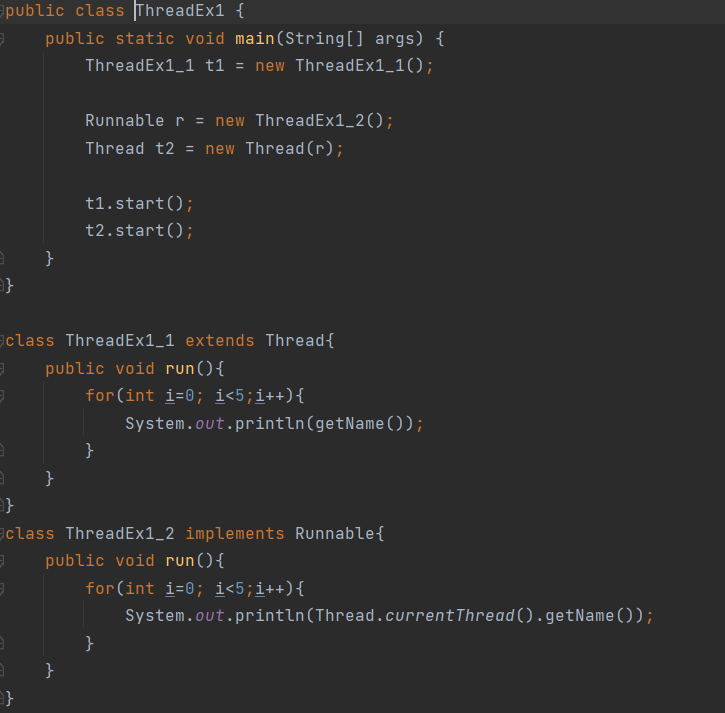
쓰레드를 구현하는 두가지 방법
ThreadEx1_1의 경우 Thread클래스를 상속받아 쓰레드를 구현한 방식이고 ThreadEx1_2의 경우 Runnable인터페이스를 상속받아 인스턴스를 구현한 후 Thread클래스의 생성자의 매개변수로 Thread를 구현한 방식이다.
Runnable인터페이스를 상속받아 구현하는 경우 해당 클래스의 인스턴스를 생성하여 Thread클래스의 생성자 매개변수로 넣어 Thread를 생성해주어야한다.
main메서드에서 처럼 생성된 인스턴스 객체의 start()메서드를 호출하면 해당 쓰레드 클래스의 run()메서드에 정의된 작업이 실행된다.
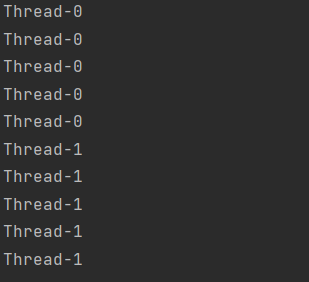
위예제의 실행결과이다. Thread이름을 가져와서 출력하는것인데 Thread클래스를 상속받은경우 getName()을 호출할경우 쓰레드의 이름을 얻을 수 있다. Runnable을 구현한 경우 run()밖에 없기 때문에 Thread.currentThread().getName()과 같이 Thread클래스의 currentThread()메서드를 호출한 후 getName()을 호출 해야한다.
쓰레드의 이름은 생성자나 메서드를 통해 지정 및 변경이 가능하다.
ex)
Thread(Runnable target, String name)
Thread(String name)
void setName(String name)
쓰레드의 실행 - start()
쓰레드를 실행시키는 것은 start()이다.
start()가 호출되면 쓰레드를 생성하여 실행대기 상태로 만든다. 이후 OS의 스케줄러에 의해 실행이 결정된다.
*Java 프로그램의 경우 JVM위에서 실행되기 때문에 보통 OS에 종속적이지 않지만 쓰레드는 JVM 과 관계없이 OS에 종속적이며 쓰레드의 실행순서는 OS스케줄러에 의해 결정된다.
java의 경우 실행후 종료된 쓰레드는 다시 실행시킬 수 없다. 즉 하나의 쓰레드에 대해 start()는 한번만 호출이 된다.
쓰레드의 작업 종료후 추가적으로 같은 작업을 위해 쓰레드를 생성해야 한다면 new 를 통해 새로운 쓰레드를 생성하여 같은작업을 실행시켜야 한다.
start()와 run()
쓰레드의 작업을 정의하는것은 run()이다. 그러나 쓰레드를 생성하고 실행시킬떄는 start()를 호출한다.
run()을 호출할 경우 Thread를 생성하는것이 아닌 단순히 해당 메서드를 호출하는 것 뿐이다.
start()는 새로운 쓰레드가 작업을 실행하는데 필요한 호출스택(call stack : 메모리상 작업공간)을 생성한 후 해당 호출스택에 run()을 호출하여 run()이 실행되도록 한다.
모든 쓰레드는 독립적인 작업을 수행하기 위해 자신만의 호출스택을 필요로 하기 때문에 새로운 쓰레드를 생성하고 실행시킬 때마다 새로 호출스택을 생성하고 쓰레드가 종료되면 호출스택을 반환(소멸)한다.
호출스택을 그림으로 나타낸 것이다. 호출스택에서 가장 위에있는 메서드가 현재 실행중인 메서드이다. 그리고 맨위(실행중)가 아닌 아래에있는 메서드들은 현재 대기상태에 있는 것이다.
멀티쓰레드 환경 즉 호출스택이 두개 이상인 경우 최상위 메서드라고 하더라도 대기상태일 수 있다.
실행중과 대기상태는 스케줄러가 결정하며 쓰레드들 우선순위에 따라 실행순서와 실행 시간을 스케줄러가 결정한다.
주어진시간동안 완료하지 못한 작업의 경우 해당 쓰레드는 대기상태로 전환되며 다시 자신의 실행차례가 오는것을 기다린다. run()에 정의된 작업을 완료한 쓰레드의경우 호출스택이 비워지며 호출스택을 반환한다.
main쓰레드
main메서드의 작업을 시작으로 다른 쓰레드들을 생성하거나 작업을 수행하는데 이떄 main메서드의 작업을 수행하는것을 main쓰레드라고 한다.
이때까지 해온 싱글 스레드 프로그래밍에서는 main메서드가 수행을 마치면 프로그램이 종료되었으나, 멀티 쓰레드 프로그래밍에서는 main메서드가 수행을 마치더라도 다른 쓰레드가 작업을 끝마치지 않았다면 프로그램은 종료되지 않는다.
프로세스는 실행중은 사용자 쓰레드가 하나도 없을 때 프로세스가 종료된다.
쓰레드는 '사용자 쓰레드(user thread)'와 '데몬 쓰레드(daemon thread)' 두개의 종류가 있다.
데몬 쓰레드의 경우 실행일지라도 사용자 쓰레드가 모두 작업을 종료하면 프로세스는 종료한다.
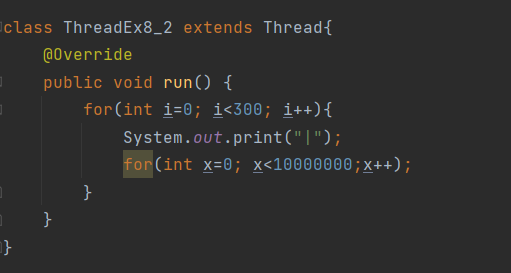
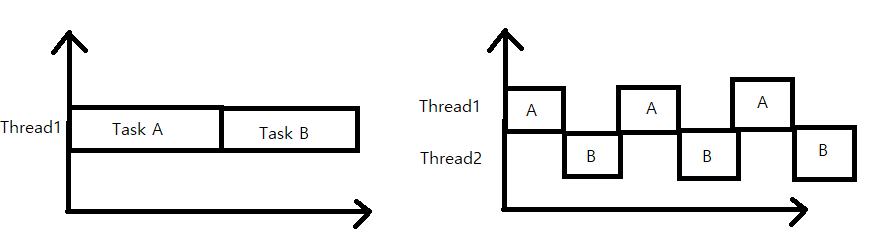
싱글쓰레드와 멀티쓰레드
왼쪽의 그림의경우 싱글스레드로 두개의 작업을 한경우이고 오른쪽의 경우 두개의 쓰레드로 두개의 작업을 한경우이다.
보통 두개의 쓰레드로 작업한시간이 한개의 쓰레드로 작업을 한경우보다 시간이 더걸린다. 그 이유는 각 쓰레드간 작업 전환(context switching)에 시간이 걸리기 떄문이다.
단순한 계산이나 하나의 자원을 사용하는경우 싱글 스레드가 더효율적이다.
여러개의 쓰레드가 서로 다른 자원을 사용하는경우 싱글쓰레드보다 멀티쓰레드가 더 효율적이다.
일반적으로 I/O 작업을 하는경우인데 네트워크로 데이터를 송수신하는경우, 사용자로부터 데이터를 입력받고 사용자에게 데이터를 출력하는경우, 프린터 출력과 같이 외부기기와의 입출력을 하는경우 등 I/O작업이 동반되는 경우 멀티쓰레드가 더 효율적이다.
JDK에서 제공하는 표준 에너테이션은 주로 컴파일러에게 유용한 정보를 제공하며, 새로운 에너테이션을 정의할때 사용할 수 있는 메타 에너테이션을 제공한다.
에너테이션 목록
표준 에너테이션
@Override : 컴파일러에게 오버라이딩 메서드라는 것을 알린다.
@Deprecated : 앞으로 사용하지 않을것을 권장하는 대상에 사용한다.
@SuppressWarnings : 컴파일러에 지정한 경고메시지가 나타나지않게해준다.
@SafeVarargs : 지네릭스 타입의 가변인자에 사용한다.
@FunctionalInterface : 함수형 인터페이스라는 것을 알릴때 사용한다.
@Native : native 메서드에서 참조되는 상수 앞에 사용한다.
메타에너테이션
@Target : 에너테이션이 적용가능한 대상을 지정할때 사용한다.
@Documented : 애너테이션 정보가 javadoc으로 작성된 문서에 포함되게 한다.
@Inherited : 에너테이션이 자손클래스에도 상속되도록 할때 사용하낟.
@Retention : 에너테이션이 유지되는 범위를 지정하는데 사용한다.
@Repeatable : 애너테이션이 반복해서 적용될 수 있도록 할 때 사용한다.
표준 에너테이션
@Override
메서드 앞에만 붙일 수 있으며, 조상의 메서드를 오버라이딩 한 메서드라는 것을 컴파일러에게 알려준다.
필수는 아니지만 사용할경우 실수를 줄일 수 있다.
오버라이딩하는 메서드의 이름을 잘못적는 경우를 방지해준다.
@Deprecated
JDK버전에 따라 기존의 기능을 대체하는것들이 나오기도한다. 이미 여러 곳에서 사용되고 있는 기능이라면 함부로 교체할 수 없기 때문에 더이상 사용을 권장하지 않는것을 알리는 @Deprecated가 생겼다.
추가적인 사용을 권장하지 않는 필드나 메서드에 @Deprecated를 사용한다.
@Deprecated가 되어있을 경우 IntelliJ에서 줄이 쳐져있다.
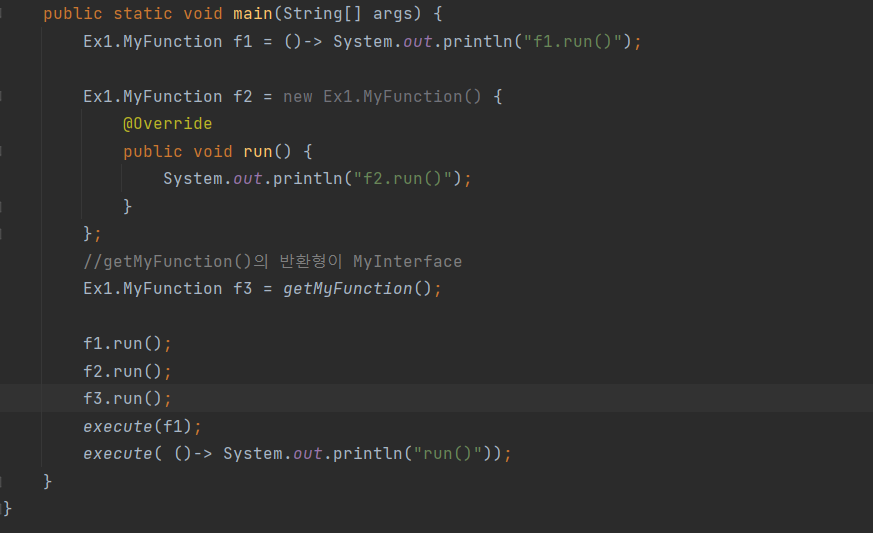
@FunctionalInterface
함수형 인터페이스(functional interface)를 선언할 때, @FunctionalInterface를 붙이면 컴파일러가 '함수형 인터페이스'를 올바르게 선언했는지 확인하고 잘못 선언되었는 경우 에러를 발생시킨다. 필수 에너테이션은 아니며, 사용시 오류를 줄일 수 있다.
ex)
@FunctionalInterface
public interface Runnalbe{
public abstract void run();
}
함수형 인터페이스는 추상메서드가 하나만 있어야 한다.
@SuppressWarnings
컴파일러가 출력해주는 경고메세지가 출력되지않도록 억제해준다.
@SuppressWarnings가 억제할 수 있는 메시지 종류는 여러가지가 있다 그중 'deprecation', 'unchecked', 'rawtypes', 'varargs' 가 주로 억제하는 메세지로 사용된다.
'deprecation'은 @Deprecated가 붙은 대상에 대한 경고를, 'unchecked'는 지네릭스 타입을 지정하지 않았을경우 발생하는 경고를, 'rawtypes'는 지네릭스를 사용하지 않아서 발생하는 경고를, 'varargs'는 가변인자의 타입이 지네릭 타입일 때 발생하는 경고를 억제할 때 각각 사용된다.
main메서드 앞에 붙임으로써 main메서드 내부에서 발생하는 deprecation과 관련된 모든 경고를 억제한다.
ArrayList객체를 생성하는곳 바로앞에 @SuppressWarnings("unchecked")를 작성함으로써 타입에 따른 경고를 억제한다.
메타 애너테이션
메타 에너테이션은 에너테이션을 위한 에너테이션이다. 에너테이션의 적용대상(target) 또는 유지기간(retention)등을 지정하는데 사용한다.