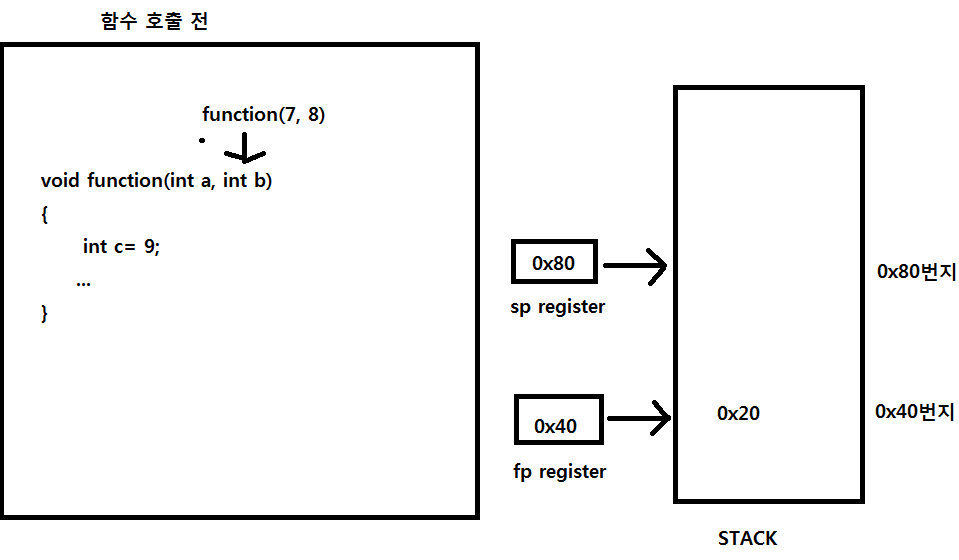
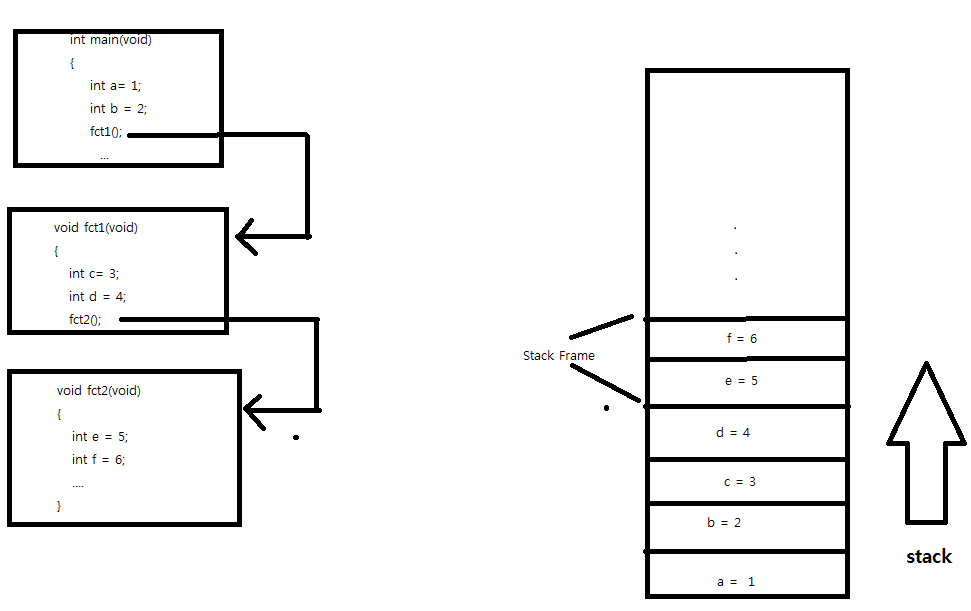
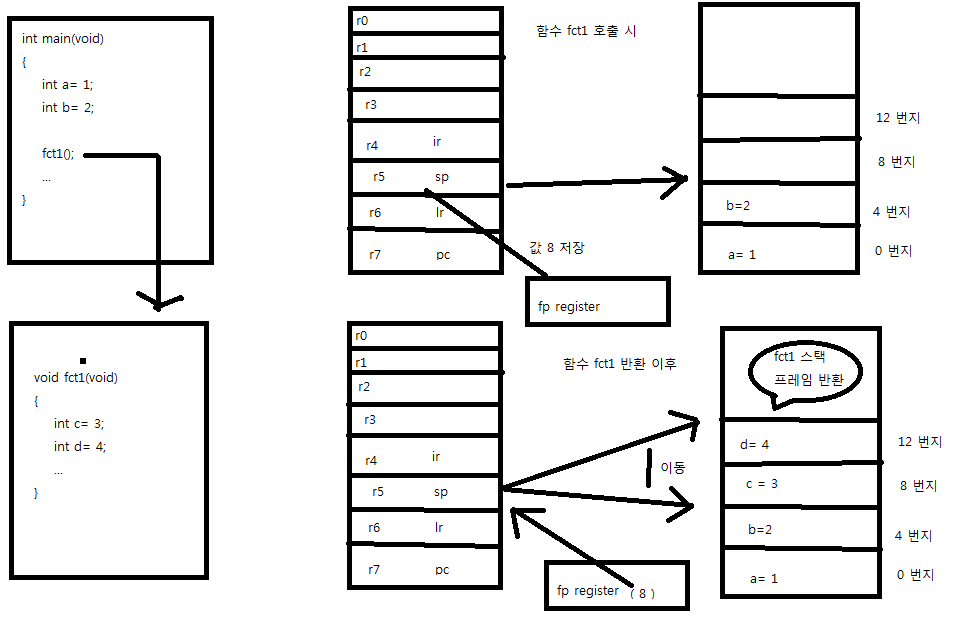
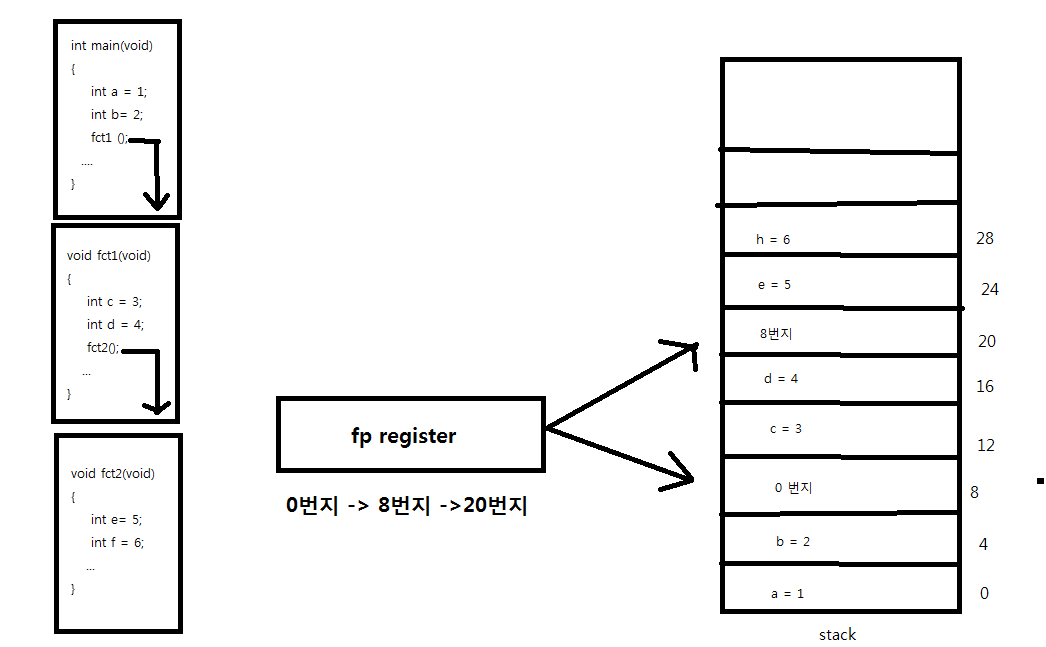
커널레벨(kernel Level)쓰레드와 유저 레벨(User Level)쓰레드
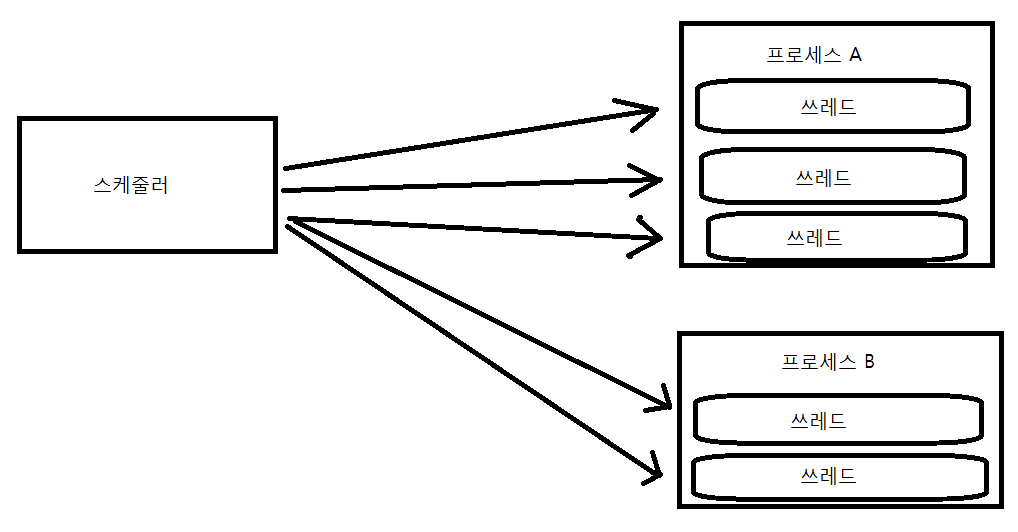
쓰레드를 생성해주는 대상은 커널일 수 있다.
이러한 경우 운영체제가 제공하는 시스템 함수 호출을 통해 쓰레드 생성을 요구해야한다. 이후 운영체제는 해당 쓰레드를 생성 및 관리하면서 새로운 흐름을 형성하도록 도와준다.
프로그래머 요청에 따라 쓰레드 생성 및 스케줄링하는 주체가 커널인 경우, 이를 가리켜 커널 레벨(kernel Level)쓰레드라 한다.
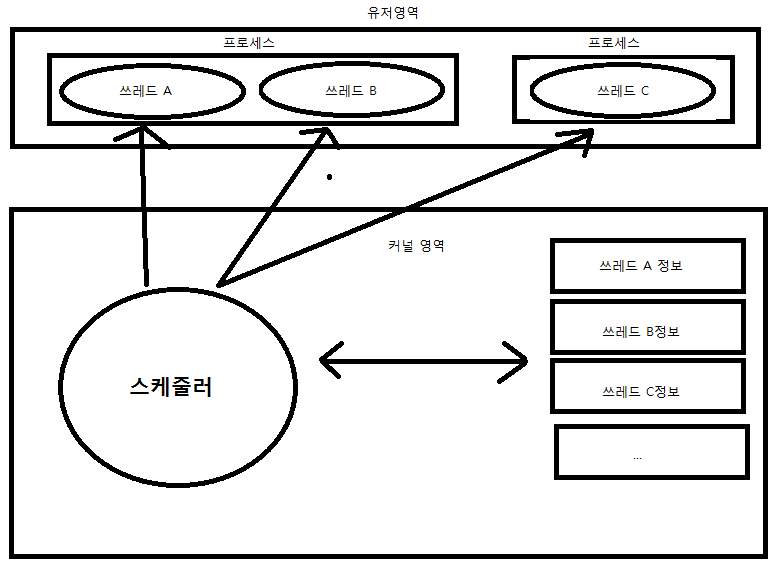
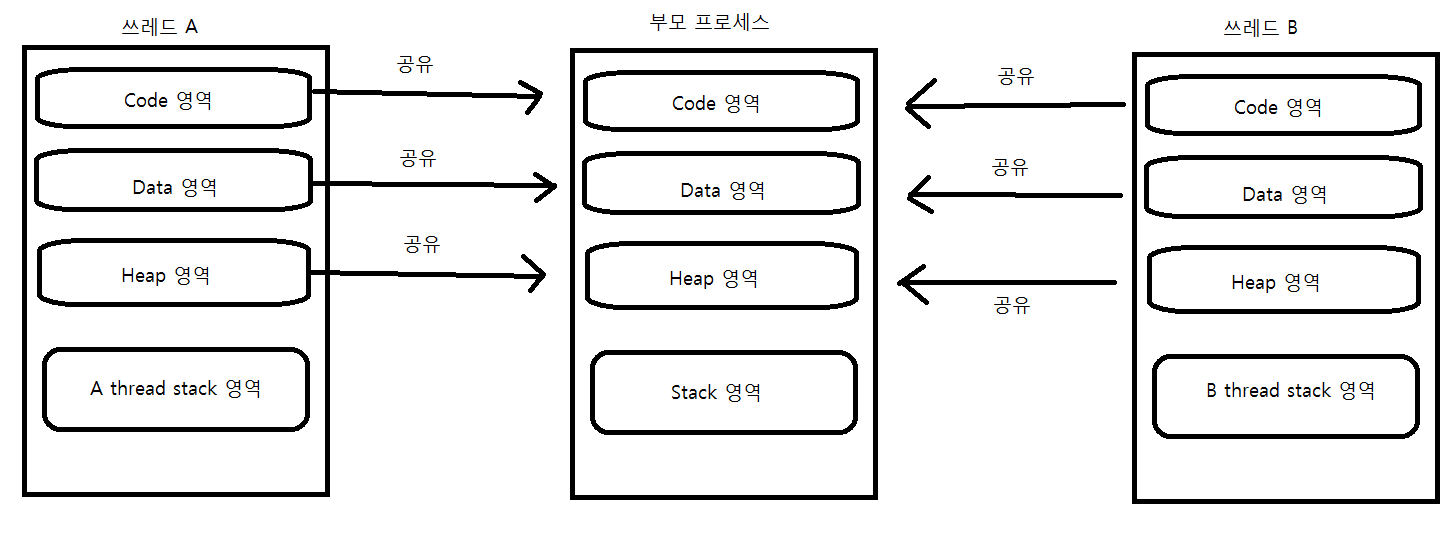
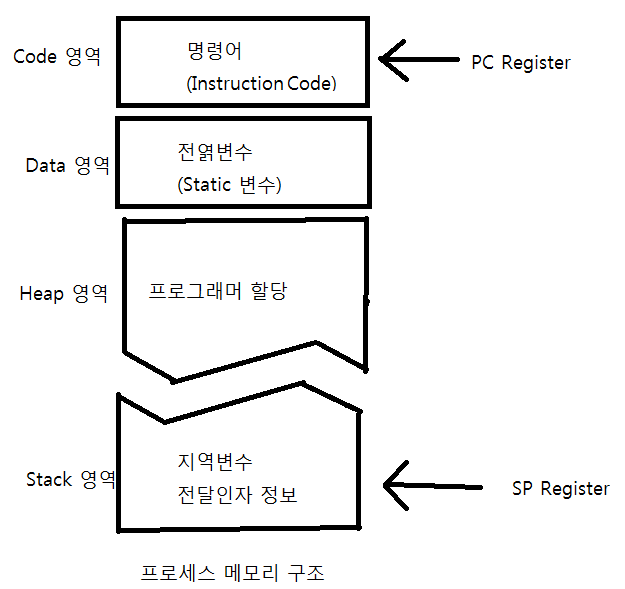
유저 영역(User 영역)은 사용자에 의해서 할당되는 메모리 공간이다. 코드 영역, 데이터 영역, 스택 및 힙 영역을 가리켜 유저 영역(User 영역)이라 한다.
커널 영역은 하낭에 프로세스에 할당된 총 메모리 공간 중에서 유저영역을 제외한 나머지 영역을 커널 영역이라 한다. 운영체제라는 하나의 소프트웨어를 실행시키기 위해서 필요한 메모리 공간을 커널영역(kernel 영역)이라 한다.
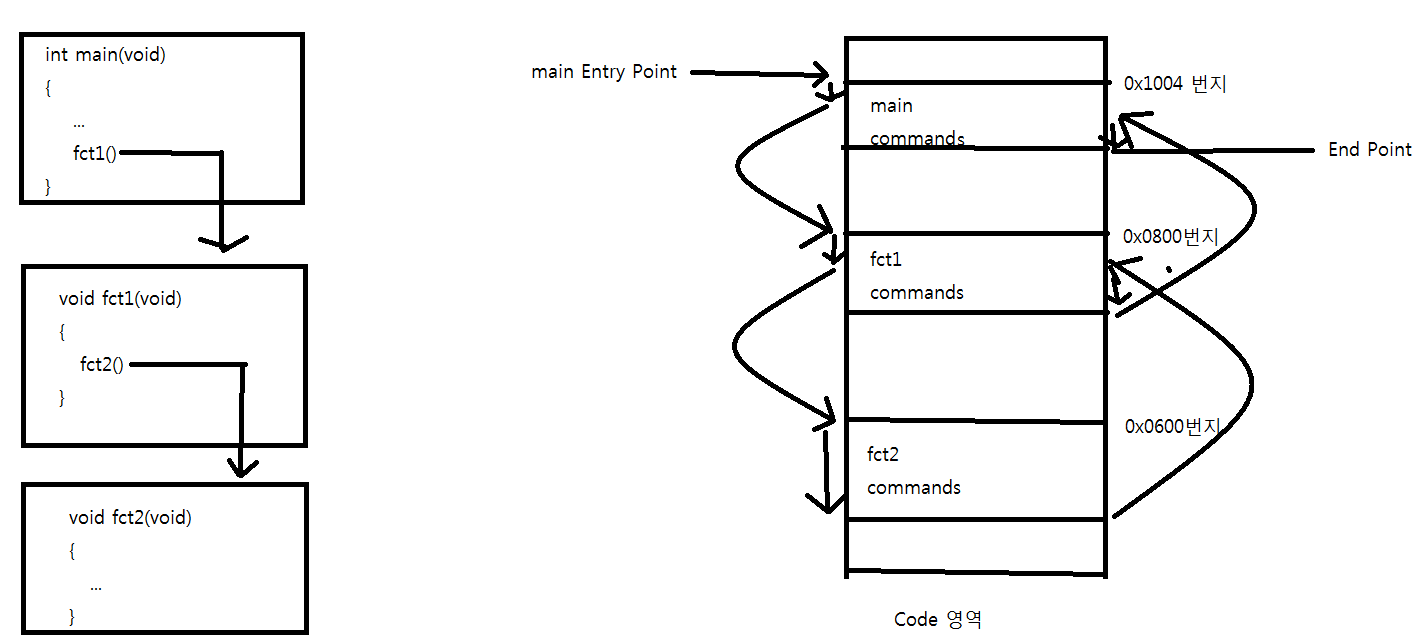
쓰레드에게 일을 시키기 위한 코드는 프로그래머가 개발하므로 쓰레드 A, B, C의 실행코드는 유저영역에 존재할 것이다. 스케줄러와 쓰레드(스케줄링 하는데 필요한 쓰레드 정보)는 커널영역에 존재한다. 이것이 커널레벨 쓰레드의 유형이다.
유저레벨(User Level)쓰레드
커널에 의존적이지 않은 형태로 쓰레드의 기능을 제공하는 라이버리를 활용할 수 있는데, 이러한 방식으로 제공되는 쓰레드가 유저레벨 쓰레드이다. 커널에서 제공하는 기능이 아니므로 실행시 유저영역에서 실행된다.
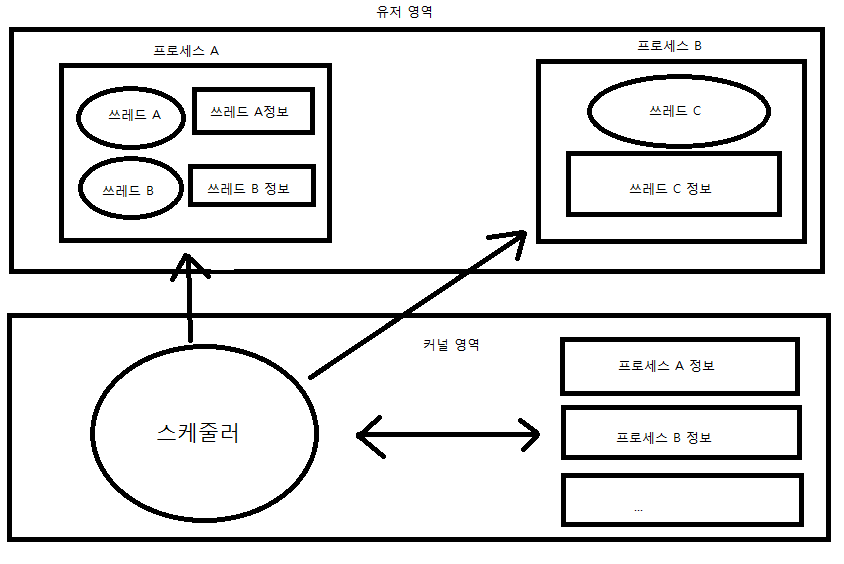
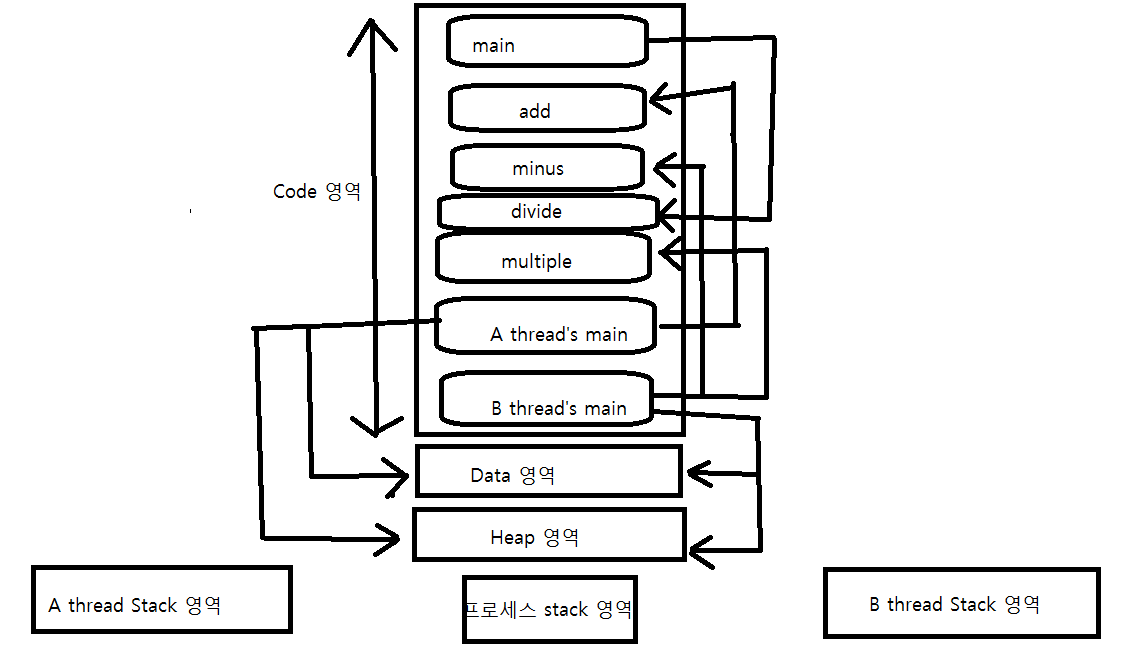
위 그림은 쓰레드를 지원하지 않는 운영체제에서의 유저레벨 쓰레드 모델을 적용한 그림이다.
운영체제가 쓰레드를 지원하지 않기 때문에 스케줄러가 스케줄링하는 대상은 프로세스이다. 쓰레드를 스케줄링하는 스케줄러는 유저영역에서 실행된다. 유저레벨 쓰레드 모델을 적용할 경우, 운영체제는 쓰레드의 존재를 알지도 확인하지도 못한다.
커널모드(kernel Mode)와 유저 모드(User Mode)
Windows 운영체제는 동작할 때 커널모드와 유저모드 중 한가지 모드로 동작한다.
메모리는 활용대상에 따라서 유저영역과 커널영역으로 나뉜다. 유저영역은 사용자가 구현한 프로그램 동작시 사용하게 되는 메모리영역이다.
커널영역은 운영체제 동작시 사용하는 메모리 영역이다. 커널이 쓰레드를 지원할 경우 쓰레드 관리가 커널영역에서 이뤄지기 때문에 커널레벨 쓰레드 모델이라 하고, 커널이 지원하지 않을 경우에 라이브러리를 통해서 제공받아야하는데 이러한 경우 유저영역에서 쓰레드의 관리가 이뤄지기 때문에 유저레벨 쓰레드 모델이라한다.
유저영역에서의 메모리 참조 오류는 실행중인 프로그램에만 영향을 미치게 되지만, 커널 영역은 커널 코드가 실행되는 영역이므로 시스템 전체에 영향을 줄 수 있다.
일반적인 프로그램은 유저모드에서 동작한다. 그러다가 커널이 실행되어야 하는 경우에는 커널모드로의 전환이 일어난다. 즉 커널영역에서 실행해야할 경우 커널모드로 전환된다. 예를 들어 프로세스가 정해진 타임슬라이스가 지나고 스케줄러가 동작하려 할때 커널모드로의 전환이 일어난다. 스케줄러는 커널의 일부에 해당하기 때문이다.
커널모드와 유저모드의 차이점
프로세스가 유저모드에서 동작할 때에는 커널영역으로의 접근이 금지된다. 유저모드에서 실행중인 프로그램이 커널영역으로 접근을 시도하면 시스템에서 오류가 발생함을 알리고 접근을 봉쇄한다.
그러나 커널 모드에서 동작할 때에는 모든 영역의 접근이 허용된다. 스케줄러의 경우 커널영역에서 커널모드로 동작하지만 유저모드의 프로세스들을 스케줄링한다.
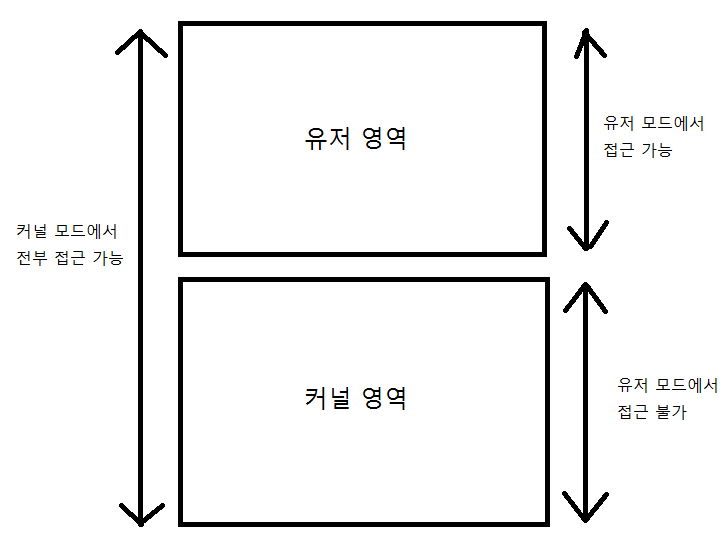
windows 운영체제 차원에서 제공하는 시스템 함스들은 커널의 구동을 필요로 한다. 따라서 이러한 함수들을 호출할 때마다 모드의 전환(커널모드 <-> 유저모드)가 발생한다. 이러한 모드의 전환은 시스템에 부담을 주기 때문에 상황에 따라 적절한 반영이 요구된다.
커널레벨 쓰레드와 유저레벨 쓰레드의 장점 및 단점
커널레벨 쓰레드의 장점 및 단점
장점 : 커널에서 제공해주기 때문에 안전성 및 다양한 기능을 제공받을 수 있다.
단점 : 커널에서 제공해 주는 기능이기 때문에 유저모드에서 커널 모드로의 전환이 빈번하게 일어난다. 따라서 성능의 저하를 발생시킬 수 있다.
유저레벨 쓰레드의 장점 및 단점
장점 : 커널은 쓰레드의 존재조차 모른다. 오로지 유저 모드로 동작하기 때문에 유저 모드에서 커널 모드로의 전환이 필요 없다. 때문에 성능이 좋다.
단점 : 예를 들어 하나의 프로세스 내에 3개의 쓰레드 A,B,C가 있다. 이중 A쓰레드가 시스템 함수를 호출했는데 커널에 의해서 블로킹 되었다. 이럴 경우 B, C도 실행되지 않는다. 운영체제는 프로세스의 존재만 알지 쓰레드의 존재를 모른다.때문에 A쓰레드가 속해 있는 프로세스 전부가 블로킹이 된다.
'Programming > Windows System Programming' 카테고리의 다른 글
| 쓰레드의 성격과 특성 (0) | 2020.07.25 |
|---|---|
| Windows에서의 쓰레드 생성과 소멸 (0) | 2020.07.23 |
| 쓰레드의 이해 (0) | 2020.07.20 |
| 함수 호출 규약 (0) | 2020.07.18 |
| 함수 호출(Procedure Call)에 의한 실행의 이동 (0) | 2020.07.18 |